Inhalt einer Datei anzeigen
Komponente: | SHOW-FILE |
Funktionsbereich: | Dateiverarbeitung |
Anwendungsbereich: | FILE |
Privilegierung: | STD-PROCESSING |
Funktionsbeschreibung
Das Kommando SHOW-FILE zeigt den Inhalt einer Datei am Terminal an, ohne dass der Anwender dazu ein Programm zur Dateibearbeitung (Editor-Programm) laden muss. Unterstützt werden folgende Dateitypen:
SAM-Datei
ISAM-Datei
PAM-Datei
PLAM-Bibliothekelement mit folgenden Satztypen:
Format-B-Sätze sind in Elementen des Typs C (ausführbares Programm), L (LLM) und H (Compiler Information File) enthalten.
Die Satzlänge beträgt immer ein Vielfaches n von 2048 Bytes (1 <= n <= 128).Format-A-Sätze können in allen Element-Typen vorkommen. Die Satzlänge ist variabel.
Enthält ein Element beide Satztypen, werden nur die Format-B-Sätze angezeigt.
Nach Eingabe des Kommandos wird die angegebene Datei bzw. das Bibliothekselement geöffnet und der erste Ausschnitt am Terminal ausgegeben. Danach werden vom Anwender weitere Anweisungen erwartet - z.B. Blättern in der Datei (vertikal/horizontal), Suchen nach einer Zeichenfolge, Ändern des Ausgabeformats, Einlesen eines anderen Elements aus der angegebenen Bibliothek, Beenden der Dateiausgabe.
Das Kommando ist nur im Dialogbetrieb anwendbar.
Mit Hilfe von XHCS kann SHOW-FILE Dateien auch angezeigen, wenn das Terminal den Datenzeichensatz nicht unterstützt (z.B. Unicode). Näheres siehe Abschnitt „Zeichensätze".
Wenn das Subsystem XHCS nicht aktiv ist, beendet sich SHOW-FILE mit der Meldung SHO0021.
Format
SHOW-FILE | Kurzname: SHF | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Operandenbeschreibung
FILE-NAME = *LIBRARY-ELEMENT(...) / <filename 1..54>
Name der auszugebenden Datei.
FILE-NAME = *LIBRARY-ELEMENT(...)
Bezeichnet das auszugebende Element einer PLAM-Bibliothek.
LIBRARY = <filename 1..54>
Name der PLAM-Bibliothek mit dem auszugebenden Element.
ELEMENT = <composed-name 1..64 with-under>(...)
Name des auszugebenden Elements. Weitere Elemente derselben Bibliothek können mit der Anweisung OPEN ohne erneuten Aufruf des Kommandos ausgegeben werden (siehe "OPEN").
VERSION = *HIGHEST-EXISTING / <composed-name 1..24 with-under>
Version des Elements (max. 24 Zeichen).
VERSION = *HIGHEST-EXISTING
Das Element mit der höchsten Version wird eröffnet.
TYPE = <alphanum-name 1..8>
Bezeichnung des Elementtyps.
OUTPUT-FORMAT =
Bestimmt das Ausgabeformat.
OUTPUT-FORMAT = *STD
SAM- und ISAM-Dateien, sowie Bibliothekselemente, die ausschließlich Format-A-Sätze enthalten, werden in einem zeichenorientierten Textformat, dem Character-Format, ausgegeben (entspricht OUTPUT-FORMAT= *CHARACTER).
Bibliothekselemente, die Format-B-Sätze enthalten, und PAM-Dateien werden im Dump-Format ausgegeben (entspricht OUTPUT-FORMAT=*DUMP), wobei Banddateien mit Nichtstandard-Blöcken nicht unterstützt werden.
OUTPUT-FORMAT = *CHARACTER
Bibliothekselemente, die Format-B-Sätze enthalten, werden nach Ausgabe der Meldung SHO0313 im Dump-Format angezeigt.
Die Daten werden in einem zeichenorientierten Textformat, dem Character-Format, ausgegeben. Die Daten werden als Zeichen ausgegeben. Für nicht abdruckbare Zeichen wird das eingestellte Ersatzzeichen ausgegeben (siehe SUBSTITUTE-CHARACTER in der Ausgabe des Kommandos SHOW-TERMINAL-OPTIONS).
Bei der Darstellung der Zeichen werden die aus der Datei gelesenen Bytes im eingestellten Datenzeichensatz interpretiert und im eingestellten Kommunikationszeichensatz dargestellt. Die Interpretation beginnt mit dem logisch ersten Zeichen des jeweiligen Satzes (abhängig vom eingestellten OFFSET).
Die Positionszählung beginnt bei 1. Zeichen mit dem Attribut nicht darstellbar oder nicht definiert, bzw. Zeichen, die nicht in den Kommunikationszeichensatz umgewandelt werden können, werden durch das eingestellte Ersatzzeichen dargestellt. Das NIL-Zeichen wird in diesem Zusammenhang (gemäß XHCS-Attribut, aber im Gegensatz zur Unicode-Konvention) als darstellbar betrachtet.
Bytesequenzen, die im Datenzeichensatz illegal sind, werden im Falle UTFE oder UTF8 byteweise in das Ersatzzeichen umgewandelt. Wiederaufsetzpunkt ist das Folgebyte des jeweils ersetzten Bytes. Illegale UTF16-Zeichen werden komplett (2 Byte) durch das Ersatzzeichen ersetzt. Ein eventuell vorhandenes isoliertes Restbyte am Satzende wird ebenfalls durch das Ersatzzeichen ersetzt.
Bei der Ausgabe in eine Datei, also falls im Prozedurmodus SYSOUT einer Datei zugeordnet ist, gelten diese Festlegungen sinngemäß, wobei als Kommunikationszeichensatz das CCS der Datei genommen wird.
Jeder Satz wird mit einem LZE-Zeichen abgeschlossen. Ein leerer Satz wird nur durch das LZE angezeigt. Das LZE wird nicht ausgegeben, falls im Prozedurbetrieb SYSOUT einer Datei zugeordnet ist.
Mit der Anweisung HEX ON kann in die Darstellung im Hex-Format umgeschaltet werden (siehe OUTPUT-FORMAT=*HEX).
OUTPUT-FORMAT = *HEX
Bibliothekselemente, die Format-B-Sätze enthalten, werden nach Ausgabe der Meldung SHO0313 im Dump-Format angezeigt.
Die Daten werden in einem zeichenorientierten Textformat, dem Hex-Format, aufbereitet. Diese Ausgabe entspricht dem Character-Format, wobei die hexadezimale Zeichenkodierung in zusätzlichen Zeilen abdruckbar dargestellt wird:
In der ersten Zeile werden die Daten als Zeichen ausgegeben (wie Character-Format).
Danach werden Paare von Hex-Zeilen ausgegeben, die den Inhalt jedes Bytes anzeigen. Die obere Zeile enthält die höherwertigen Halb-Bytes, die untere die niederwertigen Halb-Bytes.
Je nach Datenzeichensatz kann die Anzahl dieser Zeilenpaare unterschiedlich sein: Bei 7/8-Bit Zeichensätzen wird pro Satz genau ein Zeilenpaar benötigt.
Für Unicode-Dateien reichen zwei Hex-Zeilen zur Darstellung meist nicht mehr aus. Bei UTF16 sind zwei Zeilenpaare, bei UTF8 bis zu drei Zeilenpaare und bei UTFE sogar bis zu vier Zeilenpaare für die Hex-Darstellung erforderlich. Allerdings reicht bei UTF8 und UTFE im Normalfall ein Zeilenpaar aus, da die Zeichen variabel lang codiert werden, und nur für besondere Zeichen (etwa Umlaute, das „ß“ oder das Euro-Zeichen) mehr Zeilenpaare gebraucht werden.Nach einem aufbereiteten Satz wird ein Zeilenlineal als optischer Trenner zum nächsten Satz eingefügt.
Passt die Hexadezimal-Darstellung eines Satzes nicht mehr vollständig in das Datenfenster, wird dieser Satz und evtl. weitere Sätze in den verbleibenden Zeilen nur im Character-Format dargestellt und erst beim Weiterpositionieren aufbereitet.
Mit der Anweisung HEX OFF kann in die Darstellung im Character-Format umgeschaltet werden (siehe OUTPUT-FORMAT=*CHARACTER).
OUTPUT-FORMAT = *DUMP
Die Angabe ist nicht zulässig für Bibliothekselemente, die nur Format-A-Sätze enthalten, und für Banddateien mit Nichtstandard-Blöcken.
Die Ausgabe erfolgt im Dump-Format. Dazu öffnet SHOW-FILE die auszugebende Datei mit der Zugriffsmethode PAM bzw. das Bibliothekselement mit PLAM und gibt den Inhalt in Einheiten zu 2 KByte (PAM-Seite) aus:
Jede Zeile beginnt mit einer achtstelligen Sedezimalzahl, der Bytenummer des ersten in der Zeile stehenden Datenbytes innerhalb der aktuellen PAM-Seite. In Klammern folgt die Darstellung als achtstellige Dezimalzahl).
Nach der Bytenummer folgen 16 Datenbytes in Gruppen zu je 4 Bytes als Sedezimalkonstanten. Im Bildschirmformat F2 werden 32 Datenbytes angezeigt. Anschließend werden die Datenbytes als abdruckbare Zeichen dargestellt. Wie beim Character-Format wird für nichtabdruckbare Zeichen das Ersatzzeichen angezeigt. Die Zeile endet mit LZE. Die Positionszählung beginnt bei 0, d.h. das erste Byte eines Satzes besitzt die Byteposition 0.
Mehrbyte-Sequenzen variabler Länge (UTF8, UTFE) werden im druckaufbereiteten Teil so dargestellt, dass auf der Position des 1. Bytes das Zeichen ausgegeben wird, auf der Position des 2., 3. und 4. Bytes (je nach Länge der Sequenz) werden NIL-Zeichen als Füllzeichen ausgegeben. Die Interpretation beginnt mit dem ersten im Datenfenster dargestellten Byte. Mehrbyte-Sequenzen, die sich über mehrere Bildschirmzeilen erstrecken, führen zum Umbruch der jeweiligen Zeichenfolge in der Druckaufbereitung.
Mehrbyte-Sequenzen fester Länge (UTF16) werden ohne Füllzeichen dargestellt d.h. zwei Byte werden jeweils als ein Zeichen dargestellt. Wenn bei UTF16 das Problem auftritt, dass eingestreute 1-Byte-Zeichen eine falsche Interpretation bis zum Blockende verursachen, lässt sich dies durch Verschieben des dargestellten Bereichs um ein Byte leicht korrigieren. Dies gilt auch für den Fall, dass in der Datei unausgerichtete UTF16-Zeichenketten mitten im Block vorkommen, bei denen eine Korrektur mit der OFFSET-Anweisung nicht möglich wäre.
Da das Dump-Format insbesondere auch Dateien darstellen soll, die keine konsequente Codierung aufweisen, wird in Kauf genommen, dass (im Gegensatz zu den Text-Ausgabeformaten) ein horizontales Verschieben eventuell die Interpretation der Zeichen ändert. Deshalb wird auch die OFFSET-Anweisung für das Dump-Format mit der Meldung SHO0128 abgewiesen.
Kommando-Returncode
(SC2) | SC1 | Maincode | Bedeutung / garantierte Meldungen |
|---|---|---|---|
0 | CMD0001 | Kommando ohne Fehler ausgeführt | |
2 | 0 | SHO0004 | Datei ist leer (HIGHEST-USED-PAGE=0) |
1 | CMD0202 | Fehler bei Ausführung im Batchbetrieb | |
32 | SHO0001 | Interner Fehler | |
32 | SHO0003 | Fehler während der Ausführung einer Systemkomponente | |
32 | SHO0023 | PLAM-Fehler bei der Bibliotheksbearbeitung | |
64 | SHO0002 | PLAM meldete DVS-Fehler | |
64 | SHO0005 | Es werden nur SAM-, ISAM-, PAM-Dateien und PLAM-Bibliotheken unterstützt | |
64 | SHO0006 | Dateien mit RECORD-FORMAT=UNDEFINED werden nicht unterstützt | |
64 | SHO0008 | Elemente einer PLAM-Bibliothek können im Dump-Format nicht ausgegeben werden | |
64 | SHO0011 | Angegebene Datei ist keine PLAM-Bibliothek | |
64 | SHO0012 | Angegebenes Element der PLAM-Bibliothek ist unbekannt | |
64 | SHO0015 | Terminal-Typ wird nicht unterstützt | |
64 | SHO0016 | Geräte-Typ wird nicht unterstützt. | |
64 | SHO0017 | EOF bei SYSDTA im Prozedurmodus | |
64 | SHO0018 | WROUT-Fehler | |
64 | SHO0019 | Unzulässiger Zeichensatz für SYSDTA | |
64 | SHO0020 | Unzulässiger Zeichensatz für SYSOUT | |
64 | SHO0021 | XHCS nicht verfügbar | |
64 | SHO0022 | Dump-Format nicht möglich mit Zugriffsmethode SAM oder ISAM |
Zeichensätze
SHOW-FILE ab V17.1A unterstützt auch die Ausgabe von Dateien mit den Zeichensätzen UTFE, UTF8 , UTF16 und weiteren ASCII-Zeichensätzen. Da BS2000-Terminals nur ausgewählte EBCDIC-Zeichensätze direkt unterstützen, muss unterschieden werden zwischen dem Zeichensatz, in dem die Daten vorliegen bzw. interpretiert werden, und dem Zeichensatz, in dem die Daten dargestellt werden.
SHOW-FILE interpretiert die Daten im Datenzeichensatz und konvertiert sie zur Ausgabe in den Kommunikationszeichensatz. Damit können Inhalte von Dateien in allen von XHCS unterstützten Zeichensätzen mit Hilfe von XHCS ausgegeben werden. Dies gilt auch, wenn der Datenzeichensatz vom Terminal nicht unterstützt wird.
Wenn XHCS nicht aktiv ist, kann SHOW-FILE die Datei nicht ausgeben und beendet sich mit SHO0021.
Datenzeichensatz
Der Datenzeichensatz ist der Zeichensatz, in dem SHOW-FILE den Inhalt der Datei interpretiert. Als Datenzeichensatz verwendet SHOW-FILE den Zeichensatz, der im Katalogeintrag der Datei bzw. in den Metadaten des Bibliothekselementes hinterlegt ist (CCS, Coded-Character-Set). Wenn kein Zeichensatz (*NONE) eingetragen ist, wird der Zeichensatz EDF03IRV verwendet.
Wenn der Zeichensatz in XHCS nicht bekannt ist, wird ebenfalls EDF03IRV verwendet und die Warnung SHO0314 ausgegeben.
Der von SHOW-FILE automatisch eingestellte Datenzeichensatz kann mit der Anweisung CODENAME explizit geändert werden. Damit lässt sich z.B. auch eine Datei anzeigen, bei der der Zeichensatz aus dem Katalogeintrag bzw. der ersatzweise verwendete Zeichensatz EDF03IRV nicht mit dem tatsächlich verwendeten Zeichensatz übereinstimmt.
Kommunikationszeichensatz
Der Kommunikationszeichensatz ist der Zeichensatz, in dem das Arbeitsfenster am Terminal angezeigt wird und Eingaben vom Terminal entgegengenommen werden. Der Kommunikationszeichensatz muss also ein Zeichensatz sein, der vom Terminal akzeptiert wird. Beim Aufruf ermittelt SHOW-FILE den Kommunikationszeichensatz folgendermaßen:
Den Datenzeichensatz, wenn er vom Terminal akzeptiert wird.
Einen umfassenden Zeichensatz des EBCDIC-Äquivalents zum Datenzeichensatz, wenn er vom Terminal akzeptiert wird.
EDF041 (bzw. EDF03IRV bei 7-Bit-Terminals), wenn das Terminal keinen umfassenden Zeichensatz akzeptiert (z.B. Datenzeichensatz UTF16, aber das Terminal unterstützt kein UTFE).
Das führt dann etwa zu folgenden Ersetzungen:
Original | EBCDIC-Äquivalent | Vom Terminal akzeptiert |
|---|---|---|
ISO88591 | EDF041 | EDF041 |
UTF16 | UTFE | UTFE |
EDF03DRV | EDF03DRV | EDF041 |
Der von SHOW-FILE automatisch eingestellte Kommunikationszeichensatz kann mit der Anweisung TERMINAL auch explizit geändert werden.
Eingabe- und Ausgabezeichensatz
Im Prozedurmodus (siehe "SHOW-FILE im Prozedurmodus") verwendet SHOW-FILE folgende Zeichensätze:
als Eingabezeichensatz für das Lesen der Anweisungen:
Kommunikationszeichensatz, wenn SYSDTA Primärzuweisung besitzt (Terminal)
CCS der Datei, der SYSDTA zugewiesen ist
als Ausgabezeichen für die Ausgabe der Daten:
Kommunikationszeichensatz, wenn SYSOUT Primärzuweisung besitzt (Terminal)
CCS der Datei, der SYSOUT zugewiesen ist
Der Eingabe- und Ausgabezeichensatz muss jeweils ein EBCDIC-Zeichensatz sein. Wenn das nicht der Fall ist, gibt SHOW-FILE die Meldung SHO0019 (Eingabezeichensatz) oder SHO0020 (Ausgabezeichensatz) aus und beendet sich.
Anzeige nicht darstellbarer Zeichen
Ein Bytecode kann aus folgenden Gründen nicht darstellbar sein:
Der Bytecode ist in XHCS mit dem Attribut „nicht darstellbar“ gekennzeichnet (z.B. Steuerzeichen).
Der Bytecode ist im Zeichensatz nicht definiert (z.B. X'B5' in EDF03IRV).
Der Bytecode ist im Zeichensatz illegal (z.B. X'5454' in UTFE, zwei Mehrbyteeinleiter hintereinander).
Der Bytecode kann nicht in den Kommunikationszeichensatz konvertiert werden (z.B. X'B5' = '§' in EDF041 mit Kommunikationszeichensatz EDF03IRV).
An Stelle des nicht darstellbaren Bytecodes wird das Ersatzzeichen ausgegeben, das in den Terminal-Optionen als SUBSTITUTE-CHARACTER eingestellt ist (siehe Kommando SHOW-TERMINAL-OPTIONS).
Bei illegalen Bytesequenzen werden die einzelnen Bytes der Sequenz byteweise durch das Ersatzzeichen ersetzt. Wiederaufsetzpunkt ist das Folgebyte des jeweils ersetzten Bytes.
Bei Dateien im Zeichencode UTF16 tritt gelegentlich das Problem auf, dass ein einzelnes Byte in die eigentliche UTF16-Sequenz eingestreut ist.
Ein typischer Fall ist, dass der UTF16-Sequenz ein 1-Byte langes Druckervorschubsteuerzeichen vorgeschaltet ist (z.B. bei IBM-Druckdateien). Eine solche Datei kann vernünftig angezeigt werden, wenn mit Hilfe der Anweisung OFFSET die ersten n Bytes jedes Satzes ignoriert werden.
SHOW-FILE im Prozedurmodus
Wenn beim Aufruf des Kommandos der Auftragsschalter 5 eingeschaltet ist, arbeitet SHOW-FILE im Prozedurmodus, d.h. es liest seine Eingaben von SYSDTA und schreibt seine Ausgaben nach SYSOUT.
Beim Lesen von SYSDTA beträgt die maximale Satzlänge 80 Zeichen.
Wenn eine FIND-Anweisung oder eine OPEN-Anweisung unvollständig bis zu einer Unterbrechungsstelle eingegeben wurde, wird der nächste eingelesene Satz als Fortsetzungszeile interpretiert.
Wenn SYSDTA bzw. SYSOUT dem Terminal zugeordnet sind, erfolgt das Lesen bzw. Schreiben im Kommunikationszeichensatz. Wenn sie einer Datei zugeordnet sind, ist das das jeweilige CCS der Datei. In diesem Fall sind nur EBCDIC-Zeichensätze zugelassen (auch der Kommunikationszeichensatz kann nur ein EBCDIC-Zeichensatz sein), damit die Anweisungen interpretiert werden können.
Im Prozedurmodus werden der Eingabe- und der Ausgabezeichensatz bei INFORMATION mit ausgegeben.
Die vorletzte Zeile des Arbeitsfensters enthält nur die Statusanzeige. In der letzten Zeile erscheint der RDATA-Prompt, falls SYSDTA einem Terminal zugeordnet ist.
Bei der Ausgabe wird der Bildschirm in seinem normalen Aufbau mit allen Steuerzeichen nach SYSOUT ausgegeben. Die abschließenden LZE-Zeichen werden bei Dateiausgabe nicht ausgegeben.
Ausgabe auf dem Bildschirm
SHOW-FILE stellt die geöffnete Datei bzw. das Bibliothekselement formatiert am Bildschirm im so genannten Arbeitsfenster dar. Die Größe des Arbeitsfensters ist abhängig von den Eigenschaften der verwendeten Datensichtstation bzw. Terminal-Emulation. Bei einem Terminal 975x stehen 24 Zeilen mit je 80 Zeichen für die Bildschirmdarstellung zur Verfügung. Für ein Terminal 9763 gelten im Startformat (Format F1) dieselben Werte. Hier sind mit der Anweisung VDT (siehe „VDT - Bildschirmformat neu einstellen") auch Formate mit anderen Werten einstellbar (Formate F2, F3 oder F4).
Für Terminals, die das Format F1 nicht unterstützen, wird das jeweils unterstützte Format als Startformat verwendet.
Das Arbeitsfenster unterteilt den Bildschirm in 3 Bereiche mit unterschiedlichen Funktionen:
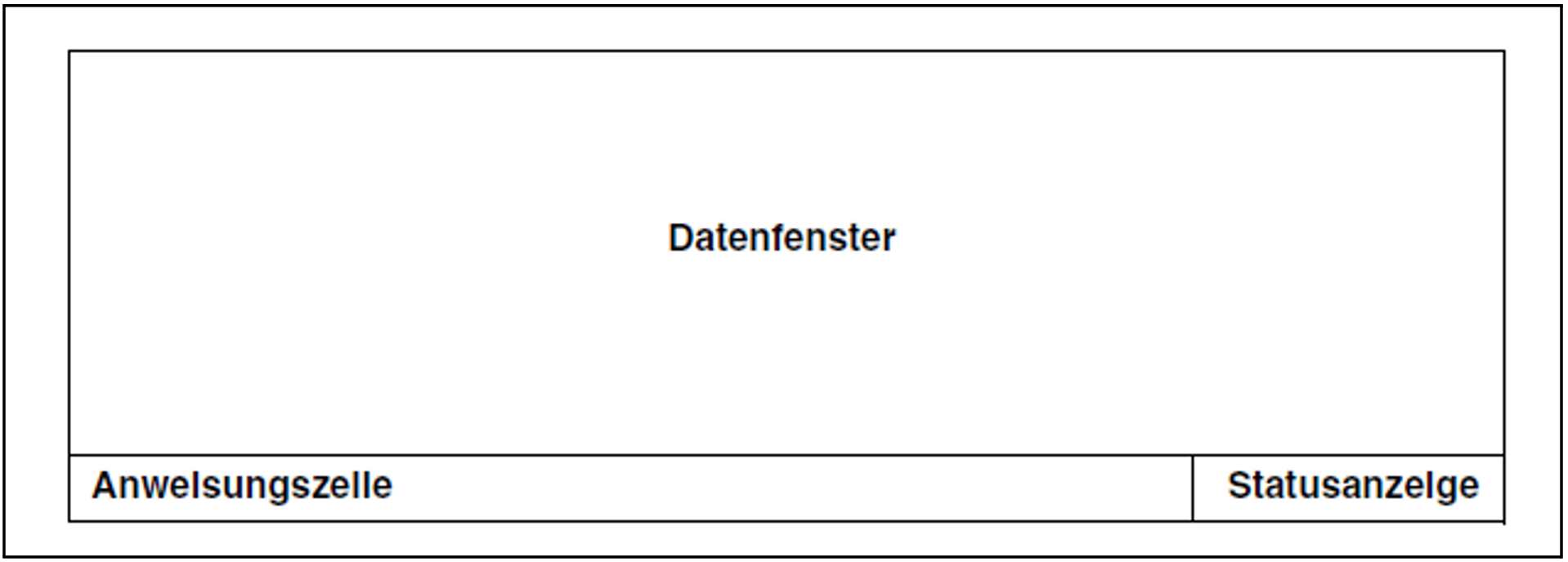
Datenfenster
Im Datenfenster werden die Daten der Datei bzw. des Bibliothekselements ausgegeben. Dazu stehen alle Bildschirmzeilen mit Ausnahme der letzte Zeile jeweils in voller Länge zur Verfügung. Im Standardfall sind das 23 Zeilen mit je 80 Spalten. Mit Einstellung eines anderen Bildschirmformats (siehe Anweisung VDT, "VDT - Bildschirmformat neu einstellen") ändern sich die Werte entsprechend.
Bei Bedarf werden die unteren Zeilen des Datenfensters für die Ausgabe von Infozeilen (2 oder 6 Zeilen, siehe Anweisung INFORMATION), für die Meldungsausgabe (1 Zeile) oder zur Bereitstellung von Fortsetzungszeilen (bis zur maximalen Zeilenzahl des Datenfensters minus 1) verwendet. Nach einem Bildschirm-Refresh (z.B. mit [K3]) sind die urspünglichen Datenzeilen wieder sichtbar.
Anweisungszeile
Die Anweisungszeile belegt die letzte Bildschirmzeile (im Standardfall die Zeile 24) mit Ausnahme der letzten 26 Zeichen, die für die Statusanzeige reserviert sind.
Im Prozedurmodus wird diese Zeile nicht in der letzten Zeile, sondern eine Zeile darüber angezeigt. In der letzten Zeile wird der RDATA-Prompt sichtbar und die Anweisungen können dort eingegeben werden.
Statusanzeige
Die Statusanzeige informiert über den Dateityp und über Positionsmerkmale des gezeigten Dateiausschnitts. Die Anzeige hat folgendes Format:
'BLANK'<typ>*<bezug><richtung><satznr>(<satzpos>)
Es bedeuten:
Position | Inhalt | Bedeutung und Wertebereich |
1 | 'BLANK' | Leerzeichen |
2 | <typ> | Dateityp: I (=ISAM), S (=SAM), P (=PAM) oder L (=PLAM) |
3 | * | Trennzeichen |
4 | <bezug> | Bezugsposition für
Bei PLAM-Bibliotheken (Dateityp=L) wird der PLAM-Satzart angezeigt. |
7 | <richtung> | Richtung gibt das Vorzeichen der Satznummer relativ zur Bezugsposition an: + oder - |
8 | <satznr> | Satznummer relativ zur Bezugsposition (siehe <
Bei Satznummern mit mehr als 10 Stellen wird der höherwertige Teil abgeschnitten: Angezeigt werden das Zeichen # und danach die letzten 9 Stellen der Satznummer. |
18 | ( | Trennzeichen |
19 | <satzpos> | Satzposition, d.h. Nummer des ersten Zeichens auf dem Bildschirm. Bei PAM-Dateien wird die Position innerhalb der PAM-Seite angegeben. |
25 | ) | Trennzeichen |
26 | Nicht belegt bzw. [LZE] im Prozedurmodus |
Beispiel
S*SOF+ 1( 1)
Maximale Zeichen- bzw. Byteposition
Horizontales Positionieren ist beim Character- und Hex-Format bis zur maximalen Zeichenposition, beim Dump-Format bis zur maximalen Byteposition möglich. Die maximale Zeichen- bzw. Byteposition ist unabhängig davon, ob Sätze dieser Länge existieren.
Die maximale Zeichenposition beim Character- und Hex-Format gibt an, wie lang ein Satz dieser Datei (theoretisch) maximal sein kann. Dies gilt unabhängig davon, ob die Datei überhaupt Sätze mit dieser Länge enthält. Die Existenz eines Satzlängenfelds wird dabei berücksichtigt, nicht aber andere Datei- oder Geräte-Eigenschaften.
Bei SAM- und ISAM-Dateien mit fester Satzlänge ist die maximale Zeichenposition genau die im Katalog festgelegte Satzlänge.
Bei SAM- und ISAM-Dateien variabler Satzlänge ist die maximale Zeichenposition gleich der Blockgröße minus 4.
Bei Bibliothekselementen, die ausschließlich Format-A-Sätze enthalten, ist die maximale Zeichenposition 32764.
Die maximale Byteposition beim Dump-Format beträgt bei Dateien 2047 (PAM-Seite) und bei Bibliothekselementen mit Format-B-Sätzen 256 KByte-1.
In den Textformaten wird höchstens so weit nach rechts positioniert, dass in der ersten Spalte des Datenfensters die maximale Zeichenposition angezeigt wird.
Im Dump-Format wird höchstens so weit nach rechts positioniert, dass in der ersten Byteposition des Datenfensters die maximale Byteposition angezeigt wird.
Anweisungen eingeben
In die Anweisungszeile können eine oder mehrere Anweisungen eingegeben werden. Beim Eingeben von mehreren Anweisungen sind diese durch Semikolon voneinander zu trennen.
Die Anweisungen werden in EBCDIC interpretiert. Groß-/Kleinschreibung wird nur innerhalb von C-Strings der FIND-Anweisung unterschieden, wenn dies mit dem Operanden LOWER oder mit der Anweisung LOWER voreingestellt wurde. Bei Schlüsselwörtern wird Groß-/Kleinschreibung ignoriert.
Bei der Eingabe werden NIL-Zeichen wie Leerzeichen behandelt.
Wenn der Auftragsschalter 5 eingeschaltet ist, arbeitet SHOW-FILE im Prozedurmodus (siehe „SHOW-FILE im Prozedurmodus").
Kommandos können erst wieder nach Beendigung von SHOW-FILE eingegeben werden (z.B. /HELP-MSG-INFORMATION zur Erläuterung einer Fehlermeldung).
Mit der Taste [K3] lässt sich der Bildschirminhalt wiederherstellen, wenn er beispielsweise durch eine Meldung des Operators überschrieben worden ist.
Fortsetzungszeilen
Der Platzbedarf für die Anweisungen OPEN oder FIND kann mehr als eine Zeile betragen. Ist die Anweisungszeile mit einer Anweisung voll geschrieben und die Anweisung noch unvollständig, werden die nötigen Fortsetzungszeilen angeboten.
Bei Eingabe einer Suchzeichenfolge wird so lange eine Fortsetzungszeile angeboten, bis die maximale Suchzeichenlänge von 256 Bytes (256 Zeichen bei C-String bzw. 512 Zeichen bei X-String) erreicht ist oder ein abschließendes Hochkomma eingegeben wird. Bei Überschreiten der maximalen Suchstringlänge wird die Eingabe mit der Meldung SHO0113 abgebrochen.
Es werden maximal soviele Fortsetzungszeilen angeboten bis noch eine Datenzeile sichtbar ist. Wenn die Anweisung danach noch unvollständig ist, wird die Eingabe mit der Meldung SHO0101 abgebrochen.
Unterbrechung langlaufender Anweisungen
Positionieren und Suchen in großen Dateien kann viel Zeit in Anspruch nehmen. Für solche Fälle können langlaufende Anweisungen des SHOW-FILE-Kommandos mit der [K2]-Taste unterbrochen werden. Die Unterbrechung ist bei folgenden Anweisungen möglich:
sequenzielles Vorwärtspositionieren mit +n
sequenzielles Rückwärtspositionieren mit -n
Stringsuche mit FIND (nicht für ISAM-Schlüssel)
Im Prozedurmodus ist die Unterbrechung mit der [K2]-Taste nicht möglich.
Nach einer Unterbrechung der oben genannten Anweisungen wird die Warnung SHO0307 ausgegeben und SHOW-FILE wartet auf die nächste Eingabe. Die Bildschirmausgabe erfolgt ab der gerade erreichten Position. Die Vorbelegung der Anweisungzeile ist abhängig von der unterbrochenen Anweisung (vgl. „Vorbelegungen der Anweisungszeile").
Vorbelegungen der Anweisungszeile
Im interaktiven Dialog belegt SHOW-FILE die Anweisungszeile nach Eingabe einer Positionieranweisung bzw. nach den Anweisungen FIND und OPEN mit einer plausiblen Folgeanweisung vor. Dies ermöglicht z.B. ohne erneute Eingabe von „+“ nur mit [DUE] durch die Datei zu blättern.
Nach Aufruf von SHOW-FILE ist die Anweisungszeile zunächst mit „+“ vorbelegt, wenn die Datei mehr als einen Satz enthält.
Eingabe | Vorbelegung mit | Keine Vorbelegung |
|---|---|---|
+[n] | +[n] | Es wird nur noch ein Satz angezeigt. |
++ | - | Es existiert nur ein Satz. |
-[n] | -[n] | Es wird der erste Satz angezeigt. |
-- | + | Es existiert nur ein Satz. |
>[n] | >[n] | Maximale Zeichen- oder Byteposition ist erreicht. |
<[n] | <[n] | Erste Zeichen- oder Byteposition wird angezeigt. |
<< | > | |
FIND string | FIND [REVERSE] | Es wurde kein Treffer gefunden. |
OPEN | + | Das Element enthält nur einen Satz. |
Die Anweisungzeile wird in folgenden Fällen nicht vorbelegt:
SHOW-FILE wurde im Prozedurmodus aufgerufen (Auftragsschalter 5 ist gesetzt).
Die Datei besteht aus nur einem Satz.
Bei Fehlern wird die letzte Eingabe nochmals in der Anweisungszeile ausgegeben. Wenn die Anweisungszeile überschrieben wurde, kann die Vorbelegung mit [K3] wieder sichtbar gemacht werden.
Übersicht der Anweisungen
Die folgende Tabelle listet alle Anweisungen in der Reihenfolge, in der sie nachfolgend beschrieben werden auf. Anweisungsnamen und Operanden sind von rechts nach links bis zur Eindeutigkeit abkürzbar.
Anweisung | Funktion |
++ | |
+[n] | |
-[n] | |
-- | |
Rn | |
<< | |
<[n] | |
>[n] | |
Sn | |
FIND | |
LOWER | Umsetzung von Kleinbuchstaben in Suchzeichenfolgen voreinstellen |
HEX | |
OFFSET | |
CODE-NAME | |
TERMINAL | |
VDT | |
INFORMATION | |
OPEN | |
END | |
Anweisungen für vertikales Positionieren
Die aktuell eingestellte Zeichen- bzw. Byteposition wird beim vertikalen Positionieren (Blättern) nicht verändert. Das gilt auch, wenn die neu dargestellten Sätze kürzer als die eingestellte Position sind.
++
| Positioniert an das Dateiende, d.h. der letzte Satz wird (wenn möglich) in der letzten Zeile des Datenfensters angezeigt. In den Textformaten wird so positioniert, dass der letzte Satz möglichst weit unten im Datenfenster dargestellt wird. Im Dump-Format wird auf den letzten Satz positioniert. Für Banddateien wird diese Anweisung mit der Meldung |
-- | Positioniert an den Datei-Anfang, d.h. der erste Satz wird in der ersten Zeile des Datenfensters angezeigt. |
+[n]
| Positioniert in der Datei vorwärts (in Richtung Dateiende). Wenn n nicht angegeben wird, wird um die Zeilenanzahl des Datenfensters vorwärts positioniert. Wenn im Hex-Ausgabeformat noch nicht aufbereitete Sätze sichtbar waren, wird auf den ersten nicht aufbereiteten Satz positioniert. Dabei werden in den Textformaten ggf. verdeckte Zeilen berücksichtigt. Es wird höchstens bis zum letzten Satz vorwärts positioniert. Wenn n darüber hinausreicht, wird auf den letzten Satz positioniert und die Meldung |
-[n] | Positioniert in der Datei rückwärts (in Richtung Dateianfang). Wenn n nicht angegeben wird, wird so positioniert, dass der Vorgängersatz des ersten im Datenfenster sichtbaren Satzes möglichst weit unten im Datenfenster dargestellt wird. Im Hex-Ausgabeformat wird sichergestellt, dass dieser Satz aufbereitet dargestellt wird. Damit der erste Satz im Datenfenster auch aufbereitet dargestellt werden kann, werden ggf. am Datenfensterende nochmals Sätze dargestellt, die bereits im aktuellen Datenfenster zu sehen waren. Es wird höchstens bis zum ersten Satz zurück positioniert. Wenn n darüber hinausreicht, wird auf den ersten Satz positioniert und die Meldung |
Vertikal positionieren auf einen bestimmten Satz
Rn
| Positioniert auf den n-ten Satz, bei der Darstellung im Dump-Format auf die n-te PAM-Seite. Die Sätze der Datei werden als fortlaufend nummeriert betrachtet. Das gilt auch für Bibliothekselemente, bei denen die Nummerierung pro Satzart angezeigt wird. Bei n=0 wird auf den ersten Satz positioniert. Wenn n größer ist als die Nummer des letzten Satzes, wird auf den letzten Satz positioniert und die Meldung |
Anweisungen für horizontales Positionieren
<<
| Verschiebt den Satzausschnitt nach links an den Satzanfang. |
<[n] | Verschiebt den Satzausschnitt zeichen- bzw. byteweise nach links (in Richtung Satzanfang). n bestimmt die Anzahl Zeichen bzw. Bytes der Verschiebung. Wenn n nicht angegeben wird, gilt folgende Voreinstellung:
Wenn n größer ist als die aktuelle Zeichen- oder Byteposition, wird auf die erste Zeichenposition bzw. das erste Byte (Byteposition 0) positioniert und die Meldung |
>[n] | Verschiebt den Satzausschnitt zeichen- bzw. byteweise nach rechts (in Richtung Satzende und darüber hinaus). n bestimmt die Anzahl Zeichen bzw. Bytes der Verschiebung. Wenn n nicht angegeben wird, gilt folgende Voreinstellung:
Es wird aber höchstens soweit nach rechts positioniert, dass in der ersten Spalte des Datenfensters die maximale Zeichenposition eines Satzes bzw. dass in der ersten Byteposition des Datenfensters die maximale Byteposition eines Satzes angezeigt wird (siehe „Maximale Zeichen- bzw. Byteposition"). |
Horizontal positionieren auf ein bestimmtes Zeichen oder Byte
S[n]
| Positioniert den angezeigten Satzausschnitt auf die n-te Zeichen, bei der Darstellung im Dump-Format auf das n-te Byte innerhalb der PAM-Seite. Akzeptiert werden Werte mit n=<integer 0..2147483647>. Führende Nullen werden ignoriert. Voreinstellung: n = 1. Es wird höchstens soweit nach rechts positioniert, dass in der ersten Spalte des Datenfensters die maximale Zeichenposition eines Satzes bzw. dass in der ersten Byteposition des Datenfensters die maximale Byteposition eines Satzes angezeigt wird (siehe „Maximale Zeichen- bzw. Byteposition"). |
FIND - Zeichenfolge oder ISAM-Schlüssel suchen
Die Anweisung FIND sucht nach Zeichenfolgen oder ISAM-Schlüssel und positioniert auf den ersten Treffer.
Format:
|
|
Bedeutung der Operanden:
| Gibt an, dass die Suchzeichenfolge als ISAM-Schlüssel interpretiert werden soll. Eine Suchzeichenfolge, die nicht der Schlüssellänge entspricht wird bei weniger Zeichen rechts mit NIL-Zeichen aufgefüllt oder bei mehr Zeichen rechts abgeschnitten. Die Operanden ALL und REVERSE werden ignoriert. Wenn die aktuelle Datei nicht mit ISAM geöffnet ist, weist SHOW-FILE die Anweisung mit der Meldung |
| Suchzeichenfolge (Zeichenfolge mit maximal 256 Zeichen aus dem Kommunikationszeichensatz bzw. dem SYSDTA zugeordneten CCS). Hochkommas innerhalb der Suchzeichenfolge müssen verdoppelt werden. Wenn die Zeichenfolge zu lang ist, wird die Anweisung mit Für die Suche wird die Zeichenfolge in den Datenzeichensatz konvertiert. Falls das nicht möglich ist,wird die Anweisung mit |
| Suchzeichenfolge in hexadezimaler Form (Zeichenfolge mit maximal 512 Hexadezimalzeichen). Es muss eine gerade Anzahl von Zeichen angegeben werden, sonst wird die Anweisung mit Wenn die Zeichenfolge zu lang ist, wird die Anweisung mit |
| Gibt an, ob Kleinbuchstaben in der Suchzeichenfolge in Großbuchstaben umgesetzt werden sollen. Wenn dieser Operand nicht angegeben wird, gilt die Voreinstellung der LOWER-Anweisung (siehe „LOWER - Umsetzung von Kleinbuchstaben in Suchzeichenfolgen voreinstellen"). |
| Kleinbuchstaben bleiben erhalten. Ein Treffer wird nur gefunden, wenn Groß-/Kleinschreibung übereinstimmen. |
| Kleinbuchstaben werden in Großbuchstaben umgesetzt. Auch bei Eingabe von Kleinbuchstaben werden nur Großbuchstaben gefunden. |
| Stellt die treffergenaue Suchstrategie ein (siehe „Suchstrategien"). Der Operand kann nur zusammen mit einer Suchzeichenfolge angegeben werden.Bei der Suche nach ISAM-Schlüsseln wird der Operand ignoriert. |
| Kehrt die Suchrichtung um, d.h. es wird in Richtung Dateianfang gesucht.Bei der Suche nach ISAM-Schlüsseln wird der Operand ignoriert. |
Trefferanzeige bei der Suche nach ISAM-Schlüsseln
Mit Angabe des Operanden K wird die angegebene Suchzeichenfolge als ISAM-Schlüssel interpretiert und die Suche beschränkt sich auf die ISAM-Schlüssel. Für die Trefferanzeige gilt:
Die Datenausgabe erfolgt ab dem Satz mit dem angegebenen ISAM-Schlüssel, wobei die Zeichen- bzw. Byte-Position im Satz unverändert bleibt.
Existiert kein entsprechender Schlüssel, so wird die Fehlermeldung
SHO0409ausgegeben und auf den Satz mit dem nächst höheren existierenden Schlüssel positioniert. Gibt es keinen Satz mit einem höheren Schlüssel, wird auf den letzten Satz positioniert.
Suchstrategien
FIND beginnt bei einer neuen Suche (es wurde eine Zeichen- oder Bytefolge angegeben) an der momentanen Zeichen- oder Byteposition im obersten Satz, der im Datenfenster angezeigt wird. Bei der Suche nach Zeichen- oder Bytefolgen wendet die FIND-Anweisung abhängig vom Dateityp bzw. dem Operanden ALL zwei unterschiedliche Suchstrategien an:
Die satzgenaue Strategie wird bei SAM- und ISAM-Dateien und Bibliothekselementen mit Format-A-Sätzen angewendet, wenn sie in einem Text-Format angezeigt werden und der Operand ALL nicht angegeben ist. Im Trefferfall, d.h. wenn ein Satz gefunden wird, der die Suchzeichenfolge mindestens einmal enthält, wird an den Beginn des Treffersatzes positioniert. Die Suche nach dem nächsten Treffer beginnt am Anfang des auf den Treffersatz folgenden bzw. bei REVERSE am Anfang des vorhergehenden Satzes.
Die treffergenaue Strategie wird bei PAM-Dateien und Bibliothekselementen mit Format-B-Sätzen immer angewendet. Sie wird außerdem bei SAM- und ISAM-Dateien immer angewendet, wenn diese im Dump-Format angezeigt werden. In allen anderen Fällen wird sie nur angewendet. wenn der Operand ALL angegeben ist. Um treffergenau rückwärts zu Suchen wird auch die Suchreihenfolge innerhalb des Satzes umgedreht. Im Trefferfall wird auf das erste Byte der gefundenen Zeichenfolge oder Bytefolge positioniert. Wird bei der Suche nach Bytefolgen ein Treffer innerhalb eines in mehreren Bytes codierten Zeichens gefunden, wird auf das erste Byte dieses Zeichens positioniert. Die Suche nach dem nächsten Treffer beginnt bei dem auf das erste Trefferbyte folgenden bzw. bei REVERSE dem Trefferbyte vorhergehenden Byte.
Weitere Hinweise
Die Anweisungszeile wird im Trefferfall mit FIND bzw. FIND REVERSE vorbelegt, so dass durch einfaches Drücken von [DUE] die Suche in der gleichen Richtung fortgesetzt werden kann. Wenn die fortgesetzte Suche (FIND ohne Suchzeichenfolge) keinen weiteren Treffer ergibt, wird die Meldung
SHO0303ausgegeben und nicht mehr vorbelegt.Wenn bereits beim ersten Suchen (FIND mit Suchzeichenfolge) kein Treffer gefunden, wird, wird die Fehlermeldung
SHO0408ausgegeben. Um die gesamte Datei rückwärts nach der treffergenauen Strategie zu durchsuchen, muss vorher auf das letzte Zeichen oder Byte des letzten Satzes (oder dahinter) positioniert werden.Wenn kein Operand oder nur der Operand REVERSE angegeben ist, wird die Suche mit der zuletzt angegebenen Suchzeichenfolge fortgesetzt. Dabei wird ggf. die Suchrichtung geändert. Wenn keine Suchzeichenfolge gespeichert ist, wird die Anweisung mit der Meldung SHO0401 abgewiesen.
LOWER - Umsetzung von Kleinbuchstaben in Suchzeichenfolgen voreinstellen
Die Anweisung LOWER bestimmt, ob SHOW-FILE Kleinbuchstaben innerhalb der Suchzeichenfolge in Großbuchstaben umsetzen soll, wenn bei einer FIND-Anweisung der Parameter LOWER nicht angegeben ist.
Format: LOWER
[
ON
/
OFF
]
Bedeutung der Operanden:
| Kleinbuchstaben bleiben erhalten, wenn innerhalb einer Suchanweisung keine andere Angabe erfolgt. |
| Kleinbuchstaben werden umgesetzt, wenn innerhalb einer Suchanweisung keine andere Angabe erfolgt. |
Bei Aufruf von SHOW-FILE ist LOWER OFF voreingestellt.
HEX - Hexadezimaldarstellung ein-/ausschalten
Die Anweisung HEX schaltet zwischen den beiden Textausgabeformaten um.
Format: HEX
[
ON
/
OFF
]
Bedeutung der Operanden:
| Die Ausgabe erfolgt im Hex-Format (siehe OUTPUT-FORMAT=*HEX). Die Ausgabe erfolgt im Character-Format (siehe OUTPUT-FORMAT= *CHARACTER). |
Im Dump-Format wird die Anweisung mit der Meldung SHO0119 abgewiesen.
OFFSET - Bytes am Satzanfang ignorieren
Die Anweisung OFFSET bewirkt bei den Textformaten, dass in jedem Satz die ersten n Bytes ignoriert werden. Im Dump-Format wird die Anweisung mit der Meldung SHO0128 zurückgewiesen.
Sätze mit einer Länge <= n werden bei dieser Darstellung wie Sätze der Länge Null behandelt.
Format: OFFSET
[ n ]
Bedeutung der Operanden:
n
| Anzahl der Bytes, die am Satzanfang ignoriert werden sollen. Akzeptiert werden Werte von n=<integer 0..2147483647>. Führende Nullen werden ignoriert. |
Bei Ausführung der Anweisung wird die Zeichenposition für die Darstellung implizit auf 1 zurückgesetzt, weil sich die Zeicheninterpretation ggf. ändert.
CODENAME - Datenzeichensatz neu einstellen
Mit der Anweisung CODENAME kann der Datenzeichensatz, in dem der Inhalt der Datei interpretiert wird, explizit eingestellt werden.
Format: CODENAME
[ ccs-name ]
Bedeutung der Operanden:
css-name
| Name des einzustellenden Datenzeichensatzes (<name 1..8>). Der angegebene Zeichensatz muss XHCS bekannt sein, anderen falls weist SHOW-FILE die Anweisung mit der Meldung |
Das Umschalten des Datenzeichensatzes löst implizit eine Reihe von Aktionen aus:
- Wenn die automatische Auswahl des Kommunikationszeichensatzes aktiv ist (siehe Anweisung TERMINAL), wird dieser neu bestimmt und ggf. neu eingestellt.
- Die letzte Suchzeichenfolge wird entwertet, d.h. eine FIND-Anweisung ohne Suchzeichenfolge wird dann abgewiesen.
- Die Zeichenposition wird auf 1 bzw. die Byteposition auf 0 zurückgesetzt, da sich die Dateninterpretation evtl. geändert hat.
Die Dateiposition bleibt unverändert, damit der Anwender die Auswirkungen der Zeichensatzänderung am gerade betrachteten Satz erkennen kann.
TERMINAL - Kommunikationszeichensatz neu einstellen
Mit der Anweisung TERMINAL kann der Kommunikationszeichensatz explizit eingestellt werden.
Format: TERMINAL
[ ccs-name ]
Bedeutung der Operanden:
css-name
| Name des einzustellenden Kommunikationszeichensatzes (<name 1..8>). Der angegebene Zeichensatz muss XHCS bekannt sein und muss vom Terminal akzeptiert werden, anderen falls weist SHOW-FILE die Anweisung mit der Meldung Wenn die Anweisung ohne Operand angegeben wird, stellt SHOW-FILE wieder den automatisch ermittelten Kommunikationszeichensatz ein (siehe auch "Kommunikationszeichensatz"). |
VDT - Bildschirmformat neu einstellen
Mit der Anweisung VDT kann ein Bildschirmformat explizit eingestellt werden (siehe auch "Ausgabe auf den Bildschirm"), wenn das Terminal das angegebene Format unterstützt.
Format: VDT
[
F1
/
F2
/
F3
/
F4
]
Bedeutung der Operanden:
| Stellt das Bildschirmformat auf 24 Zeilen und 80 Spalten ein. |
| Stellt das Bildschirmformat auf 27 Zeilen und 132 Spalten ein. |
| Stellt das Bildschirmformat auf 32 Zeilen und 80 Spalten ein. |
| Stellt das Bildschirmformat auf 43 Zeilen und 80 Spalten ein. |
Die Bildschirmformate F2, F3 und F4 werden nur von Terminals des Typs 9763 unterstützt. Wenn das Terminal das angegebene Format nicht unterstützt, wird die Anweisung mit der Meldung SHO0306 abgewiesen.
INFORMATION - Informationen über Datei bzw. Bibliothekselement ausgeben
Die Anweisung INFORMATION gibt Informationen über die aktuell angezeigte Datei bzw. das aktuell angezeigte Bibliothekselement aus.
Format: INFORMATION
Für Dateien überschreibt die Informationsausgabe die letzten beiden Datenzeilen (im Standardfall Zeile 22-23). Angezeigt werden der Dateiname sowie eine Informationszeile mit den beteiligten Zeichensätzen (CCS der Datei, Datenzeichensatz und Kommunikationszeichensatz:
FILE: <filename 1..54> CCSN: FILE=<name 1..8> DATA=<name 1..8> TERM=<name 1..8>
Für Bibliothekselemente überschreibt die Informationsausgabe die 6 letzten Datenzeilen (im Standardfall Zeile 19-23). Angezeigt werden der Bibliotheksname, der Elementname, der Elementtyp, die Version, die Variante sowie eine Informationszeile mit den beteiligten Zeichensätzen (CCS der Datei, Datenzeichensatz und Kommunikationszeichensatz:
LIBRARY: <filename 1..54> ELEMENT: <composed-name 1..64> TYPE: <name 1..8> VERSION: <text 1..24> VARIANT: <integer 1..9999> CCSN: FILE=<name 1..8> DATA=<name 1..8> TERM=<name 1..8>
Die angezeigte Information kann mit [DUE] oder Eingabe der nächsten Anweisung ausgeschaltet werden. Sie ist nach dem nächsten Bildschirmaufbau nicht mehr sichtbar.
Wird INFORMATION innerhalb einer Anweisungskette eingegeben, so wird die Information bei der nächsten Bildschirmausgabe angezeigt. Die Verarbeitung der Anweisungskette wird nicht abgebrochen.
Wenn zur selben Zeit die Ausgabe einer Meldung ansteht, erzeugt INFORMATION keine Ausgabe.
Beispiel
Wird nach Eingabe von +;inf;find c'suche' die Zeichenfolge „suche“ nicht gefunden, wird keine Information, sondern nur die Meldung „SHO0408 SPECIFIED STRING DOES NOT EXIST“ ausgegeben.
OPEN - Neues Bibliothekselement ausgeben
Die Anweisung OPEN öffnet ein neues Element der beim SHOW-FILE-Aufruf
angegebenen Bibliothek. Ein bereits vorher geöffnetes Element wird automatisch geschlossen. Wenn beim SHOW-FILE-Aufruf kein Bibliothekselement sondern eine Datei angegeben wurde, wird die Anweisung mit der Meldung SHO0107 abgewiesen.
Format: OPEN
([typ[,elname[,version]]])
Bedeutung der Operanden:
| Elementtyp (siehe auch Operand TYPE). |
| Elementname (siehe auch Operand ELEMENT). |
| Version des Elements (siehe auch Operand VERSION). |
Hinweise:
- Mit dem Öffnen des neuen Elements werden der Datenzeichensatz und das Ausgabeformat entsprechend den Eigenschaften des Elements neu bestimmt.
- Der Kommunikationszeichensatz wird neu bestimmt, wenn die automatische Bestimmung aktiv ist.
- Die Position wird zurückgesetzt und die Suchzeichenfolge entwertet.
- Ein explizit eingestellter Kommunikationszeichensatz, das Bildschirmformat und die Voreinstellung für Umsetzung von Kleinbuchstaben in Suchzeichenfolgen (siehe Anweisung LOWER) bleiben erhalten.
- Wenn das Element nicht existiert, gibt SHOW-FILE die Meldung
SHO0407aus. Es ist dann kein Bibliothekselement geöffnet und SHOW-FILE akzeptiert nur die Anweisungen OPEN und END.
END - Dateiausgabe beenden
Die Anweisung END schließt die aktuell angezeigte Datei bzw. das Bibliothekselement und beendet SHOW-FILE. Die abschließende Meldung SHO0500 enthält den vollständigen Dateinamen der zuletzt angezeigten Datei bzw. den Bibliotheksnamen, den Elementnamen, die Version, die Variante und den Elementtyp des zuletzt angezeigten Bibliothekelements.
Format: END
Die Taste [K1] wirkt wie die END-Anweisung. Angaben in der Anweisungszeile werden in diesem Fall aber ignoriert.
Hinweise für Plattendateien
- Dateien mit BLOCK-CONTROL-INFORMATION=*PAMKEY oder *WITHIN-DATA-BLOCK können Blocklücken aufweisen. Dies sind logische Blöcke, die zwar bereits für eine Datei reserviert, aber aktuell noch nicht belegt sind. Man erkennt diese logischen Blöcke an ihrer ungültigen CFID. Da diese Blöcke noch Daten enthalten können, die nicht zur Datei gehören, werden PAM-Seiten solcher Blöcke als „leere“ PAM-Seiten (2048 * X'00') ausgegeben. Zusätzlich kommt ein Hinweis in Form einer Meldung, dass
- die gerade gezeigte PAM-Seite (OUTPUT-FORMAT=*DUMP) bzw.
- eine oder mehrere PAM-Seiten (bei PAM-Dateien und OUTPUT-FORMAT=*CHAR oder *HEX)
nicht belegt ist/sind.
Dies gilt für alle PAM-Dateien unabhängig vom OUTPUT-FORMAT und für alle ISAM- und SAM-Dateien bei OUTPUT-FORMAT=*DUMP.
- Tritt bei der Ausgabe einer SAM-Datei der DMS-Fehler '0BB7' auf (Satz mit fehlerhafter Länge gelesen), wird SHOW-FILE mit einer Meldung abgebrochen.
- Folgende Plattendateien werden mit SHARED-UPDATE=*YES geöffnet:
- PAM-Dateien unabhängig vom Anzeigeformat
- ISAM-Dateien nur bei Anzeige in einem der Textformate
Schreibzugriffe einer anderen Task sind möglich, wenn die Datei dabei ebenfalls mit SHARED-UPDATE=*YES geöffnet wird.
Hinweise für Banddateien
Das Kommando SHOW-FILE kann auch den Inhalt von Banddateien anzeigen. Dabei ist Folgendes zu beachten:
- Das Positionieren ans Dateiende (mit ++) ist nicht möglich und wird mit der Meldung
SHO0129abgewiesen. - Banddateien vom Typ PAM (in allen Ausgabeformaten) und Banddateien vom Typ SAM (im Dump-Format) können nur angezeigt werden, wenn der Katalogeintrag die korrekte Anzahl von Datenblöcken enthält.
- Banddateien vom Typ SAM ohne Katalogeintrag (Foreign-Datei) können in den Text-Formaten wie folgt angezeigt werden:
- Katalogeintrag mit IMPORT-FILE erstellen, z.B.:
/import-file support=*tape(volume=vol001,dev-type=tape,file-name=band.datei) - TFT-Eintrag mit ADD-FILE-LINK für die Datei mit dem Linknamen DSHOW und die Zugriffsmethode SAM erstellen, z.B.:
/add-file-link link=dshow, file-name=band.datei, access-method=*sam - Die Datei mit SHOW-FILE öffnen, z.B.:
/show-file band.datei
- Die Anzeige sollte sequenziell und während eines einzigen SHOW-FILE-Aufrufs bis zum Dateiende erfolgen. Bei Beendigung der SHOW-FILE-Ausgabe wird der aktuelle Blockzähler als Gesamtanzahl der Datenblöcke der Datei (siehe Kommando SHOW-FILE-ATTRIBUTES, Ausgabefeld BLK-COUNT) in den Katalogeintrag übernommen.
Wird der SHOW-FILE-Aufruf vor dem Dateiende beendet, wird bei nachfolgenden SHOW-FILE-Aufrufen die Datei nur noch bis zu diesem Datenblock angezeigt, die restlichen Datenblöcke können nicht mehr angezeigt werden.
Um dies zu beheben muss ggf. der Katalogeintrag gelöscht und wieder neu erstellt werden (Kommandos EXPORT-FILE und IMPORT-FILE). - Banddateien vom Typ SAM ohne Katalogeintrag können im Dump-Format nicht angezeigt werden. Banddateien vom Typ PAM ohne Katalogeintrag können grundsätzlich nicht angezeigt werden.
Beispiele
Hex-Format-Darstellung einer Datei im Zeichensatz (=Datenzeichensatz) UTFE:
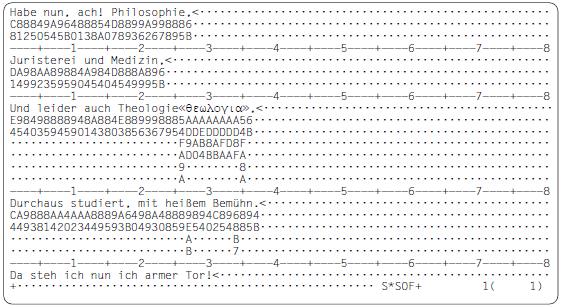
Dump-Format-Darstellung einer Datei im Zeichensatz (=Datenzeichensatz) UTFE:
