Primary index block
From each of the data blocks described in section "ISAM data block", DMS takes the highest key value and places it, together with the logical block number of the data block, in a primary index block. In NK-ISAM, a “separator” is formed from this key; in K-ISAM, any existing value and/or logical flags are also included in the index entry.
Each primary index block consists of precisely one PAM page. If one primary index block is too small to hold the pointers to all existing data blocks, not only a second primary index block at the same level is created, but also a primary index block at a second level and the entries in this block point to the primary index blocks at the first level. This results in an index tree.
Primary index tree
The tree structure of an ISAM file is formed by the primary index and data blocks. The data blocks form the lowest level, which is called level 0. All higher levels contain only primary index blocks. The highest level always consists of a single primary index block, which is called the root of the index tree and is the entry point for all accesses to the records of the ISAM file.
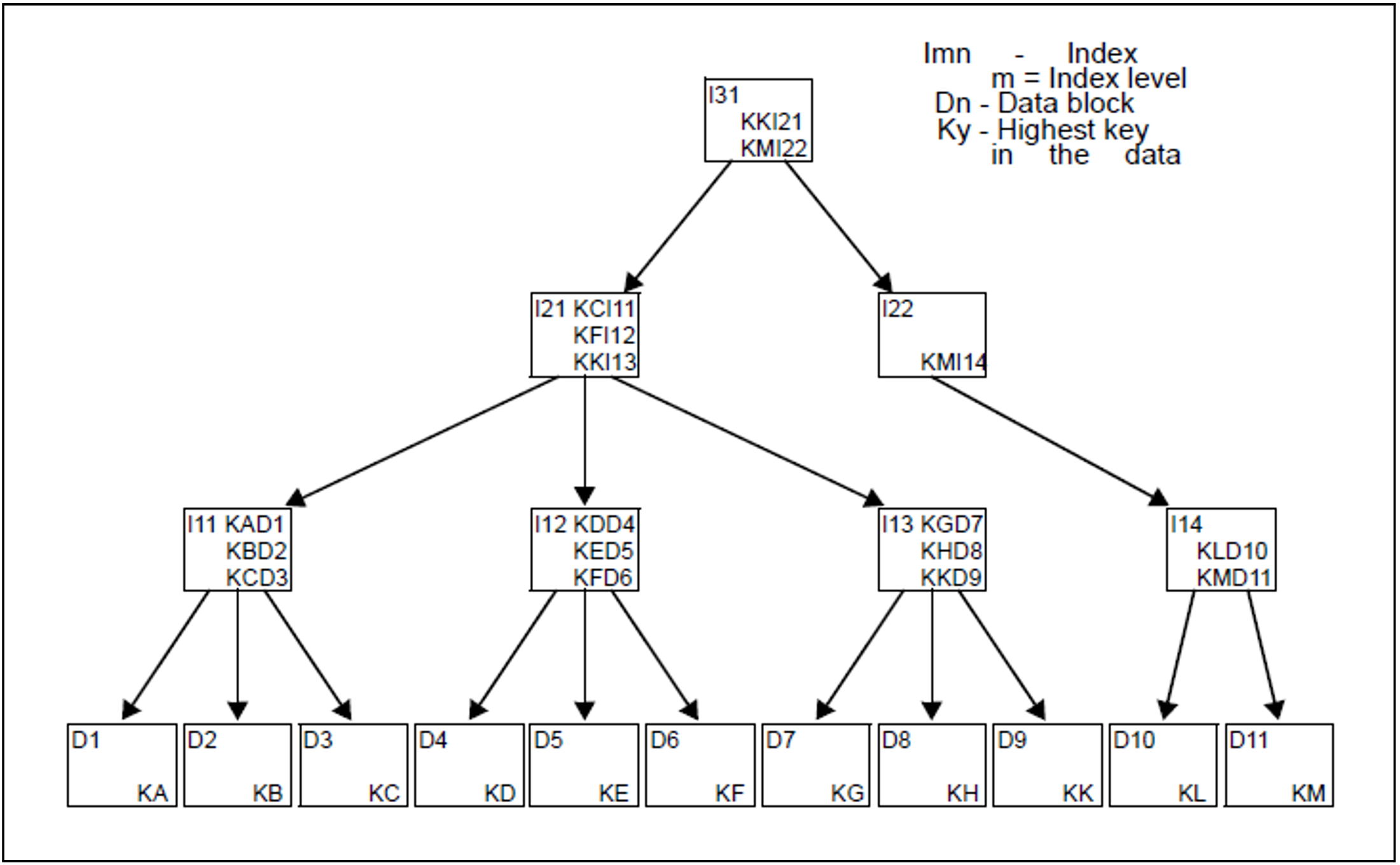
Primary index treeThe file shown in this example has three primary index levels (I1, I2, I3) and the data level (D). The root of the primary index tree is primary index block I31. The letters Ky represent the highest key in each data block. These keys are placed, together with pointers to the associated data blocks, in the primary index blocks of level I1. The highest key in each primary index block I1n is placed, this time with a pointer to the associated primary index block, in a primary index block of level I2. Since one primary index block is still not enough to accommodate all index entries at this level, there has to be a third index level (I3), which consists of a single primary index block, namely the root of the tree.
Secondary index block (NK-ISAM)
For each secondary key defined for a file, DMS creates a secondary index consisting of one or more secondary index blocks. In this index, it creates an entry for each value of this secondary key which occurs in the file. This entry contains the primary key values of the associated record as a pointer. Entries with the same secondary key value are combined to form one record. If such a record would exceed the boundaries of a secondary index block, another record is created for the same secondary key value.
An entry in a secondary index consists of:
the secondary key value with the largest time stamp contained in the record. If the record involved is the last record with the secondary key value, it contains the value X'FF...FF' instead of the time stamp.
one or more entries: each entry consists of the primary key value of the record involved and a time stamp. If duplicate keys are not permitted for the secondary key (operand DUPEKY=NO in the CREAIX macro or DUPLICATE-KEY=*NO in the CREATE-ALTERNATE-INDEX command), each entry contains only one pointer, and this pointer's time stamp contains the maximum possible value (X'FF...FF').
A record in a secondary index block for a given secondary key value thus has the following structure:

where:
Sec-value | Secondary key value for which this record was created. |
Tm-St | Time stamp of the record. |
Tm-Sti | i=1,...,n: time stamp of entry i. |
Prim-valuei | i=1,...,n: primary key value of the record to which pointer i points |
Access to records in an ISAM file
Access via the primary key (ISAM key)
If an ISAM file is processed randomly (i.e. not sequentially), DMS must be able to retrieve any record requested by the user program. It starts the search for a record with the specified key at the highest primary index level – in the root of the primary index tree – and is then guided downwards through all existing primary index levels to the appropriate data block. In NK-ISAM, the search within a primary index block is speeded up by grouping the primary index entries into “sections”, which means that the search is executed in a series of jumps.
In the example shown in figure 32, let us assume the user wants the record with the key KI. The primary index entries in I31 show that the search must be continued in primary index block I21: the key KI is lower than KK.
The entries in primary index block I21 point to primary index block I13 for KI: KF < KI < KK.
The entries in primary index block I21 point to primary index block I13 for KI: KH < KI < KK.
The desired record can now be found quickly.
In both NK-ISAM and K-ISAM, the access paths are implemented in the form of a tree structure. However, the primary index block at the highest level in K-ISAM contains a 36-byte header with management information, while this information is kept in the control block in NK-ISAM.
The use of key compression in the primary index blocks means that the length of a primary index entry in NK-ISAM is virtually independent of the actual key length. The number of index entries and index levels thus depends only on the number of data blocks.
In K-ISAM, the number of primary index blocks and primary index levels of an ISAM file depends not only on the number of data blocks in the file, but also on the length of the ISAM key or, if value and/or logical flags are used, on the length of the ISAM primary index: no key compression is used; if the primary index area is 255 bytes long only 4 index entries will fit into one primary index block.
Access via a secondary key (NK-ISAM)
If the user requests a record with the aid of a secondary key, DMS first searches the associated secondary index blocks for an record with this value. If such a record exists, DMS uses the entries in the record to determine the primary key value of the desired record. If there are several entries in the record (which happens in the case of duplicate secondary keys), DMS always uses the first pointer. With this primary key value, DMS then searches for the desired record as described in the preceding section.
Searching for a record with the aid of a secondary key is thus less efficient than retrieving the record via its primary key: approximately twice the number of I/O operations and twice the CPU time are required.