In accordance with the description of XML documents which is based on file processing, XML documents are also processed using slightly extended statements for file processing:
OPEN DOCUMENT:
Starts processing of an XML (sub)document and assignment of a record description entry from the FD of the XML document to a document in the tree presentation.START ATTRIBUTE or START ELEMENT:
Positions in the tree on the basis of a record description entry which has already been assigned.READ ATTRIBUTE or READ ELEMENT:
Transfers data from the tree to corresponding data items of the assigned record description entry.CLOSE DOCUMENT:
Ends processing of an XML (sub)document.
As with file processing, error handling is possible using statement-specific phrases (AT END, INVALID KEY) or by means of USE statements. The data item of the FILE STATUS clause describes the result of the statement; here new XML-specific values are possible in addition to the values already defined.
When processing an XML document, the following is important for understanding the statements:
Nodes from the tree are assigned to the data items of a record description entry which have an IDENTIFIED clause.
The current assignment is stored.
The current assignment has an influence on subsequent statements.
The current assignment can be modified by statements.
Element Position Vector (EPV)
The assignment of nodes in the tree to their description in the COBOL program is recorded using the Element Position Vector. The name corresponds to the 'Element Position Vector' used in the Technical Report "Native COBOL Syntax for XML Support" – however, it is used for assigning all nodes, element and attribute nodes. An internal management structure of the COBOL system for processing an XML document is concerned here: each node described in the program (i.e. only data items with an IDENTIFIED clause) has an entry in the EPV. The position of a currently assigned node from the tree is stored in this entry – this status is also referred to below with ’the data item has a position'.
If no node has yet been assigned to a data item, or if the assignment has been made invalid by a statement, this special status is also recorded in the EPV. The interpretation of the stored positions by subsequent statements also depends on whether they resulted from a READ, OPEN or START statement.
Furthermore, a data item can only have a valid position if all the data items which are superordinate to it in the structure also have a valid position.
Assigning nodes
An assignment only modifies the EPV, but does not transfer data.
Requirement for assigning a node from the tree to a data item
The nodes in the tree and in the IDENTIFIED clause of the data item must be of the same type, i.e. both must be element nodes or both must be attribute nodes.
The ’matching’ of the name specified in the IDENTIFIED clause with the name of the node in the tree:
In the case of a BY phrase the names must be identical, except for trailing blanks.
In the case of a USING phrase any arbitrary name from the tree is regarded as matching.
Assignment procedure
|
Example 12-39 Principle of assigning nodes
XML document | Node | COBOL data structure | EPV |
<a> | 1 | FD xml-fil |
|
Comments:
Data items for values are irrelevant for assignment. They are therefore omitted in the COBOL description.
Assumption for the first step: on the COBOL side the data items at level 01 (x and z) are examined, on the XML side only node 1 – this corresponds to the behavior of an OPEN DOCUMENT statement, see also "OPEN DOCUMENT". To assign the XML document to the COBOL description a data item must be found which specifies the name of the root node 'a' in its IDENTIFIED clause, namely data item z.
In the following steps assignment is then continued on the tree side with the children of node 1 which has just been assigned - starting with the oldest, i.e. with nodes 2, 3, 4 and 6. On the side of the COBOL description only the data items with an IDENTIFIED clause which are directly subordinate to the data item to which the parent node has just been assigned (i.e. data items u and w which are subordinate to data item z) are taken into consideration here.
Node 3 with name 'b' can be assigned to data item u, and node 2 with name 'd' to data item w.
Node 4, also with name 'b', cannot be assigned: in principle data item u would come into consideration here, but u is no longer available because it has already been assigned node 3. As node 4 cannot be assigned, none of its children, their children, etc. – here only node 5 – can be considered for further assignments, either.
Node 6 also cannot be assigned as neither of the data items (u, w) which are directly subordinate to data item z specifies the name 'c' in its IDENTIFIED clause. Data item y does specify the appropriate name, but is not one of the data items taken into consideration because it is not a child of data item z.
Since node 3 was assigned to data item u, the data items (v) which are directly subordinate to data item u also come into consideration for assignments. However, as the assigned node 3 has no children, no further assignments are possible.
In the last step all the data items which were taken into consideration during the procedure to which no nodes could be assigned obtain invalid positions, these being, from the first step, data item x with its subordinate data item y, and, from the following steps, data item v.
The procedure for the assignment of nodes means:
The order of assigned sibling nodes in the tree need not be the same as the order in which they are described in the COBOL data structure.
The hierarchy of the data items in the COBOL description corresponds directly to the hierarchy of the assigned nodes in the tree. There are no gaps. For the nodes this means that if a node from the tree is assigned to a data item, its parent is also assigned to a data item of the COBOL structure.
If more than one 01 structure exists in an FD, there can only ever be valid positions in one single 01 structure.
The aim is not to create as many assignments as possible, but always to execute the assignments in the same, fixed order.
Statement sequences
In the sections below the principal effects of the statements will be explained briefly, but without any details of the syntax and any rules.
Initially a minimum amount of information which shows how the statements function in principle is offered for each topic group. This is then illustrated by means of examples with comments. Finally, important information is combined for each topic group without laying any claim to completeness. To obtain all the information on a topic, please read the relevant sections in the chapter "XML".
The statements for processing the XML document or individual parts thereof must be executed in the order shown in the figure below. Further COBOL statements for actually processing the XML data have been omitted for the sake of clarity.
{} | | Indicates repeatable individual steps Separates possible alternatives |
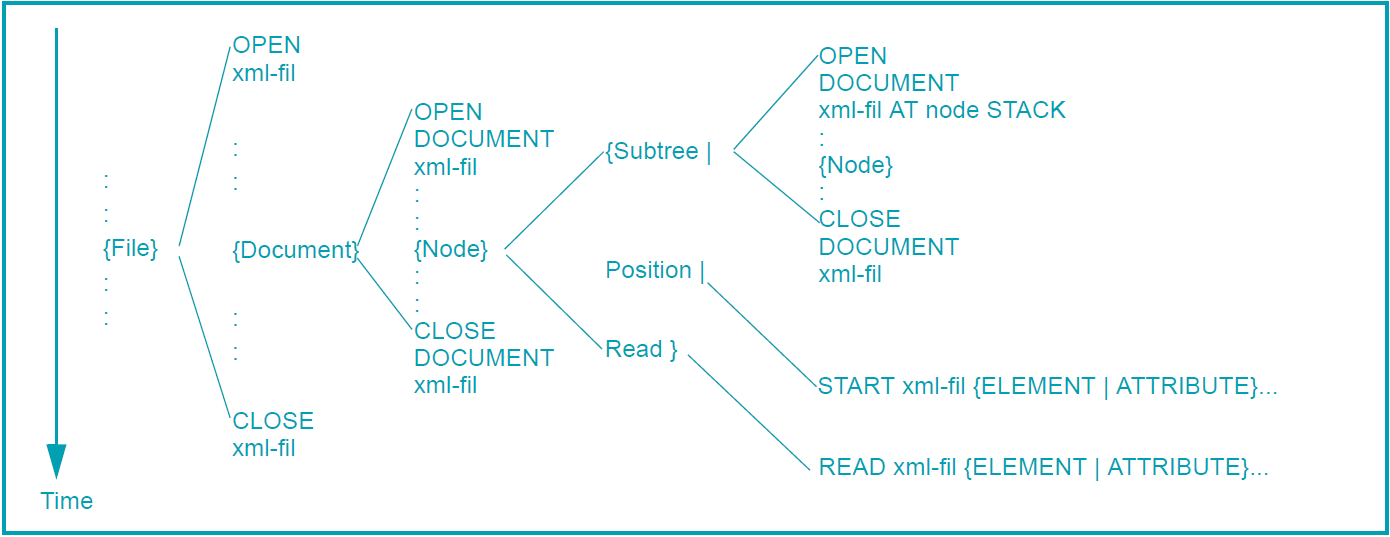
For the sake of clarity the presentation of the new statements largely dispenses with possible error situations and how these are handled. An overview of error situations is provided below in section "Error handling".
Important information on the presentation of examples 12-40 in section "OPEN DOCUMENT" through 12-56 in section "Namespace" below:
The following is displayed from left to right in the columns of the example tables:
XML document:
The XML documents have been reduced to what is important for the examples. They should not be misunderstood as well-formed XML.
To make them easier to read, the XML documents include indents/blanks and line feeds. These editing measures are not intended as part of the values of a node.
Positions which correspond to the XML nodes
COBOL description
Then, in each column, come the statements which are executed one after the other. Only the status after execution is recorded here: a node assigned in the EPV (i.e. its position) is noted in the IDENTIFIED clause for this purpose. Which statement created the position is added in parentheses:
o OPEN DOCUMENT, START r READ
All positions and contents which are modified as a result of the statement are displayed in bold print in the associated column, all unmodified values in italics.Statements and definitions which are not important for the particular case are omitted.