The Concurrent Copy (CCOPY) function offers a backup option which permits a consistent backup (incl. version backup) of a specified set of files to be produced while allowing any editing of the files to be continued. The computer center may benefit from this by saving a considerable amount of time compared with the normal backup methods.
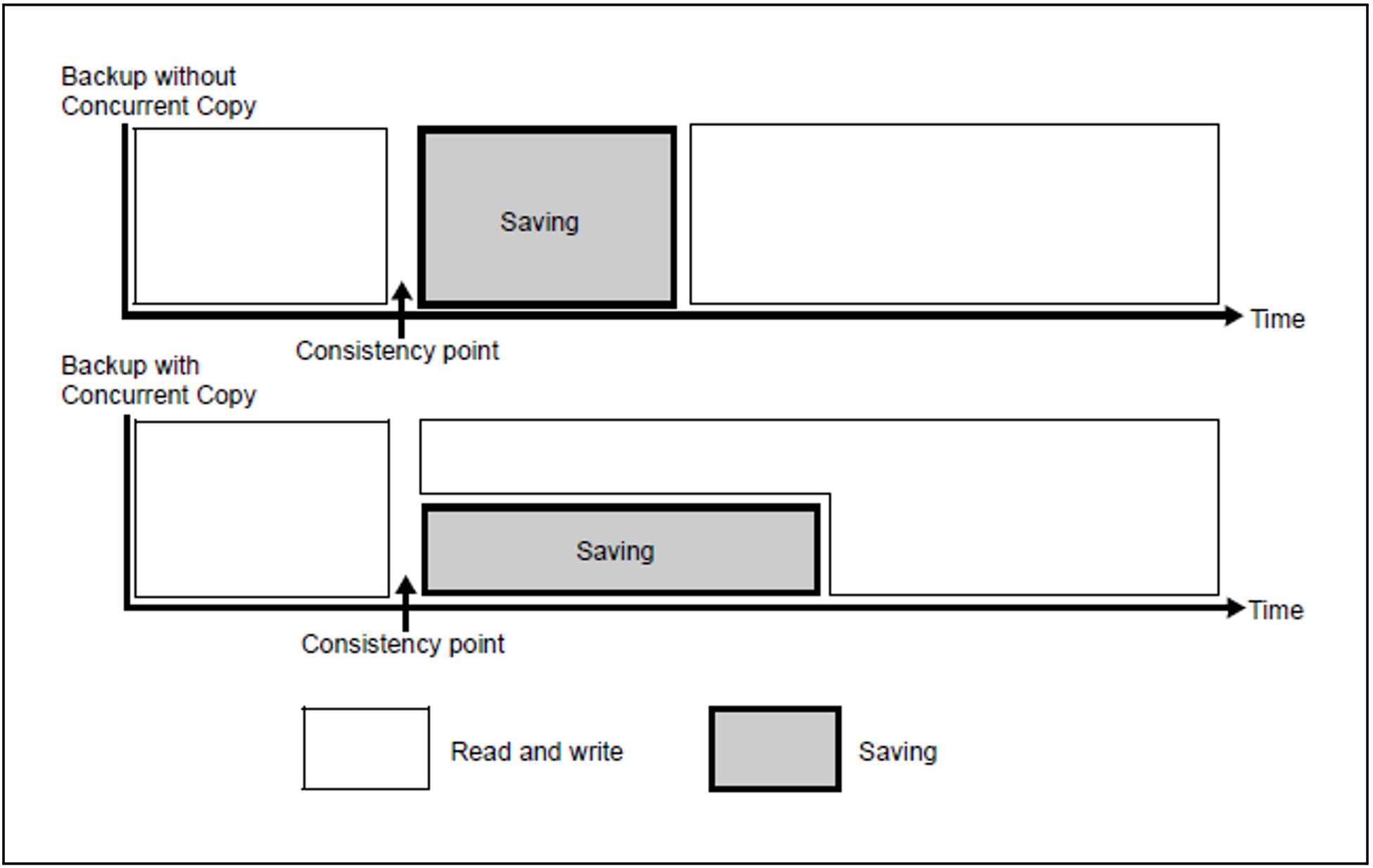
The CCOPY function is intended in particular for applications which have to remain open for extended periods but during whose execution it is nevertheless necessary to backup files. However, it requires more resources than a normal backup. The CCOPY function is activated by means of the CONCURRENT-COPY operand in the BACKUP-FILES or BACKUP-FILE-VERSIONS statements .
In order to request a backup with the CCOPY function it is necessary, when using a work file (WORK-FILE-NAME=*STD or <filename>), to define a set of files which are to be backed up in this way. This set of files may contain, for example, all the files required by the application. When the backup job is created, these files must be open at least for read access to ensure that they have a consistent status (exceptions here are online backup with SHC-OSD on "Backups with SHC-OSD" and the transfer of a Snapset backup on "Transfer of files and job variables from Snapsets to a backup archive"). The backup job must be created using //BACKUP-FILES ..., CONCURRENT-COPY=*YES; or in case of version backup, by //BACKUP-FILE-VERSIONS ..., CONCURRENT-COPY=*YES.
Once initialization is complete, the HSMS/system administrator receives messages indicating the results of this first step. If the job variable service is active in the system, the administrator can use a job variable to query whether a problem has occurred. If the backup cannot be initialized for one or more files, HSMS informs the administrator of the files which could not be processed.
The cause may be that a file was locked. The administrator can then remedy the error and repeat the HSMS statement BACKUP-FILES or BACKUP-FILE-VERSIONS in case of version backup.
If an error occurs during backup with CONCURRENT-COPY=*YES or if any files cannot be saved, the backup run is still continued for the remaining files, saving as many of the specified files as possible.
Files which could not be saved can be included in a later backup. Any files that could not be saved can be included in a subsequent backup with or without the CCOPY function. However, consistency with the files saved in the initial backup is not guaranteed in this case.
Saving with CONCURRENT-COPY=*YES stores the file. Otherwise the files will be saved one after the other.
If one of the required files cannot be found or is open, the backup is continued as if it had been started without CONCURRENT-COPY=*YES.
When saving with CONCURRENT-COPY=*YES you cannot carry out a write buffer with DAB.
Irrespective of any backup server definition, backups with Workfile are always sent to and processed on the master in the SPVS network. Backups of split-off mirrors (*BY-ADDITIONAL-UNIT) are always processed locally.
Backup with work file
The basic mechanism used as default for determining a consistency point when backing up data is to write so-called before-image files: for the duration of a CCOPY backup, whenever a block in a file forming part of the backup set is modified for the first time, then, before this happens, a copy of the as yet unmodified block is written to a work file. The CCOPY backup uses internal tables, which are updated whenever a before-image file is read, whether a block is to be read from the original file or the work file.
The work file for the before-image files can either be created by default by HSMS or be specified explicitly in the HSMS statement BACKUP-FILES or BACKUP-FILE-VERSIONS:
//BACKUP-FILES ..., CONCURRENT-COPY=*YES(WORK-FILE-NAME= -
<filename 1..54 without-gen-vers>)
or
//BACKUP-FILE-VERSIONS ..., CONCURRENT-COPY=*YES(WORK-FILE-NAME= -
<filename 1..54 without-gen-vers>)
If file sets are backed up on shared pubsets, then it is necessary to ensure that the work file is accessible on the master host or backup server of the shared pubset if this work file is explicitly specified. It is essential that the backup (but not the creation of the backup job to HSMS) is performed on the master host or backup server.
Performance
The writing of before-image files to the work file, which requires one read and one write operation per (large) block, together with the internal administration of the before-image files, places an increased demand on operating resources: I/O, CPU time and memory space for the work file. The increased CPU load and the additional I/O operations have a negative effect on performance. They are dependent on the location and scope of the changes that are performed to the data in question in parallel to the backup. If the system load is low, the effects are correspondingly small.
Backups with SHC-OSD
With SHC-OSD the mirroring functions of the disk storage systems are available in BS2000 as a further basic mechanism for CCOPY backups. When these functions are used, disks of a pubset within a disk storage system are mirrored on additional disks (clone units). If necessary, these additional mirror disks can be split from the original disks and processed as a pubset copy independently of the original pubset. The splitting and rejoining of the disk pairs is controlled by SHC-OSD. This function is particularly useful for backups. It is integrated in HSMS via the CCOPY subsystem. For details on the BS2000 host component for storage systems, refer to the “SHC-OSD” manual [ 23 ].
If remote mirroring in a second disk storage system is used, the splittable disks can also be used in the remote disk storage system.
For HSMS backups which use the mirroring functions of a disk storage system with SHC-OSD, mirroring must be performed on the composite pubset, i.e. for all the volumes of a pubset. The mirror disk pairs are then split on the initialization of the backup job for all the volumes of the pubsets involved. Pubset I/Os are stopped for the duration of splitting. This ensures that the following conditions are fulfilled:
The data of the file set that is to be backed up is consistent. Files opened in write mode do not result in the backup being aborted or can be saved as in a backup without CCOPY using the SAVE-ONLINE-FILES=*YES option.
The pubset metadata on the split-off mirrors (additional units or clone units) is consistent in that they permit the reconstruction of the pubset at the time of splitting.
This ensures that the consistent data status as at the start of the backup is available during the entire backup operation. Once the backup has been successfully concluded, the mirroring is automatically recommenced. This can be prevented by specifying DISCARD-COPY=*NO in the BACKUP-FILES or BACKUP-FILE-VERSIONS statements. Error handling is discussed below.
Backing up open files
When pubset copies are backed up under CCOPY, files that are still open can also be backed up. This function was designed with databases in mind (e.g. SESAM, UDS, ORACLE):
If databases are to remain permanently accessible, they cannot be run down and closed just to perform a backup. As a result, databases are usually backed up while they are still open. More detailed information on backup can be found in the manuals on the various database management systems.
The variation of online backup means that a database backup can be carried out much quicker than before, because the length of time that the database files are locked, is now much shorter, and this results in part in smaller LOG files subsequently required to reconstruct a consistent state.
Renaming mirror disks
When the disks of the pubset copy are split off, they are renamed in accordance with the following rules:
In the case of volumes which contain a period, the period is replaced by a colon, e.g. ABC.05 –> ABC:05
Volumes with names starting with the prefix PUB receive the prefix P:B, e.g.
This renaming process is necessary so that, following splitting, the volumes on the original disks and the mirror disks do not have the same names. Only in this way is it possible to address the disks of the pubset copy via a unique name.
Creating a pubset copy
When you initiate the backup, you can specify CONCURRENT-COPY=*YES(WORK-FILE-NAME=*BY-ADDITIONAL-UNIT) in the HSMS statements BACKUP-FILES or BACKUP-FILE-VERSIONS to indicate that you want to use a pubset copy. However, it should be noted that when you perform this type of backup job, the mirror disks of the pubset copy are not available for other backups. For this reason, it is necessary to coordinate backup jobs which use the same mirror disks.
Only a pubset copy saved with //BACKUP-FILES can be used to reconstruct the complete SF or SM pubset from the mirrored data volumes of the original pubset and the backed up files.
If you also wish to save open files, you must also specify SAVE-ONLINE-FILES=*YES. However, this only backs up the files that are open, for which online backup has been specified using the OPNBACK operand of the CATAL macro call (see the “DMS macros” manual [22]).
In addition, you can specify WRITE-CHECKPOINTS=*YES in order to ensure that you can restart or reset mirror disks (see below). This is recommended since it requires almost no extra effort. At the same time, the availability of the data stock in its status at the start of the backup is guaranteed for the entire duration of the backup.
Authorization for backup using SHC-OSD with assigned customer privileges
Backups based on SHC-OSD mirroring functions to a large degree demand operating resources which are not available without limit or infinitely extensible but, instead, whose use has to be precisely planned. Consequently, this type of job is reserved for systems support staff (TSOS privilege) and HSMS administrators (HSMSADM privilege). If necessary, it is also possible to assign a customer privilege in order to allow application administrators who do not possess either of these privileges to perform a backup using SHC-OSD mirroring functions. However, control of customer privileges requires the use of the SECOS software product (see the “SECOS” manual [16]). The following steps are necessary:
You define one or more customer privileges which provide authorization for this backup. These customer privileges are reported to the CCOPY subsystem in a parameter file on subsystem start.
By default, the CCOPY information file is used for this purpose:SYSSSI.CCOPY.<subsys-vers>
Alternatively, you can use START SUBSYSTEM command with
PARAMETER=‘<filename>‘ to specify a parameter file with a name of your choice; this specification has priority.The parameter file is a SAM file with variable record length and contains precisely one record. This record specifies the customer privileges for backups with SHC-OSD mirroring functions in the form of the string CU[STOMER]-PRIV[ILIGES]=(0,1,2,...,8). If only a single customer privilege is specified then the parentheses can be omitted. The value 0 means that no customer privilege is to be checked. This value is set by default in the CCOPY information file.
You use the corresponding SECOS function to assign one or more user IDs to the customer privileges for which CCOPY backups with SHC-OSD mirroring functions have been enabled as specified under point 1 (see the “SECOS” manual [16]).
Performance
CCOPY backups with SHC-OSD mirroring functions barely differ from backups without CCOPY in terms of performance: the data to be backed up is read from the split-off mirror disks, while the files that continue to be processed during the backup are located on the original disks. There is therefore no interference between the backup and the application.
Because the catalog accesses are not executed from the disks of the pubset that are running but locally from the split-off disks, it is not practical in shared-pubset mode to send the job to the pubset master to enhance performance. CCOPY backups with SHC-OSD mirroring functions are therefore executed locally on the system on which the backup call was issued.
Error handling
In the case of CCOPY backups with SHC-OSD mirroring functions, the data that is to be backed up and all the metadata for the pubsets involved is available on the pubset copies at the consistency point status at the moment the backup was started. In this way, extensive recovery measures can be performed if, as is recommended, the backup has been defined as restartable. This can be done in the HSMS statements BACKUP-FILES and BACKUP-FILE-VERSIONS or with WRITE-CHECKPOINTS=*YES during the definition of the archive.
When SHC-OSD mirroring functions are used, this specification also makes it possible to perform application-specific recovery measures. In contrast, if you specify WRITE-CHECKPOINTS=*NO then the procedure is the same as for CCOPY backups with before-image files: no restart mechanisms are provided for by HSMS/CCOPY.
Below, we present certain error scenarios and the associated restart possibilities if WRITE-CHECKPOINTS=*YES is specified:
Error during backup
Here the same applies as for backups without CCOPY: if the HSMS job has the status INTERRUPTED then it can be continued using the HSMS statement RESTART-REQUESTS. For more detailed information, see section "Restarting requests".
System failure
Backup in progress and restartable application
Once the system is available again, a warm start of the application is performed. The backup can be continued using the HSMS statement RESTART-REQUESTS. For more detailed information, see section "Restarting requests".Backup in progress and non-restartable application
Once the system is available again, the affected pubset must be reset to its consistent status at the start of the backup in order to make it possible to repeat the interrupted operation. To do this the following steps are necessary:The pubset’s original disks must be synchronized with the mirror disks. This is done using the following command. Here the pubset may not be imported:
/RESTORE-FROM-CLONE UNIT=*BY-PUBSET(PUBSET=<catid 1..4>)
(see the “SHC-OSD” manual [21]). This resets the data to its status at the last consistency point.
Next, the pubset volumes which possess the archive numbers of the mirror disks must be renamed to their original names using the PVSREN utility so that the archive numbers are again compatible with the pubset syntax. This is done using the PVSREN statement:
//RESTORE-LABELS-OF-PUBSET CATID=<catid 1..4>
(see the “Utility Routines” manual [3])
The reset pubset must be imported.
The interrupted operation must be repeated. It may also first be necessary to reissue the backup job.
Restrictions
The following restrictions apply to backups with CCOPY:
The WRITE-CHECKPOINTS and SAVE-ONLINE-FILES functions are only available for backups of pubset copies.
Private disks are not supported.
A CCOPY backup on a shared pubset with work file (WORK-FILE-NAME=*STD or <filename>) is always processed on the master. A CCOPY backup of pubset copies is executed locally on the side where the backup call was issued.
File migration is not supported during a CCOPY session.
The memory space occupied by a file which belongs to the file set that is to be backed up may not be reduced using the following BS2000 command during the entire duration of the backup:
/MODIFY-FILE-ATTRIBUTES ...,SUPPORT=*PUBLIC-DISK(SPACE=*RELEASE(...))
A file may, at any one time, form part of only one CCOPY backup. If a job for further CCOPY backup involving this file is requested then this job is rejected.
CCOPY optimizes the catalog accesses when initiating the backup of a pubset copy.
Transfer of files and job variables from Snapsets to a backup archive
In BS2000 pubset copies can be generated on the basis of Snap disks (so-called Snapsets) from which files or job variables can then be restored directly in the original pubset with the DMS command. Since the total number of these pubsets is limited for a pubset by the disk subsystem, the generation and deletion of Snapsets must take place in the same rythmn. Before a Snapset is deleted the files and job variables saved on it can be transferred to a backup archive using the HSMS statement BACKUP-FILES. The catalog ID of the pubset and the identifier of the Snapset to be saved are specified here:
//BACKUP-FILES ..., CONCURRENT-COPY=*YES(WORK-FILE-NAME= -
*FROM-SNAPSET(PUBSET-ID=<catid>,SNAPSET-ID=<snap-id>)
In contrast to the backup of pubset copies, when saving Snapsets you must bear in mind that the files and job variables do not match the current state at the time BACKUP-FILES is processed but reflect a backup status at the time the Snapset was generated. Consequently a save version generated in this way is assigned the date of Snapset generation in the backup archives.
If newer save versions already exist in the backup archive a new save file must be created in order to retain the uniqueness of the save versions within a save file. An update of the save file is rejected. The transfer of files or job variables from Snapsets should not be combined with direct backups in the same backup archive.
Data from Snapsets cannot be transferred to a version backup archive.