All client/server architectures can be divided into individual software components, known as “layers” or “tiers”. We often speak of 1-tier, 2-tier, 3-tier, and multi-tier models. It is often unclear whether these tiers exist on a physical or logical level:
Logical software tiers exist when the software is divided into modular components with clear interfaces - irrespective of how these components are distributed in the network.
Physical software tiers exist when the (logical) software components are distributed across various systems in the network.
In figure 12 on the next page, you will see the five basic client/server modules, each of which has two physical software tiers.
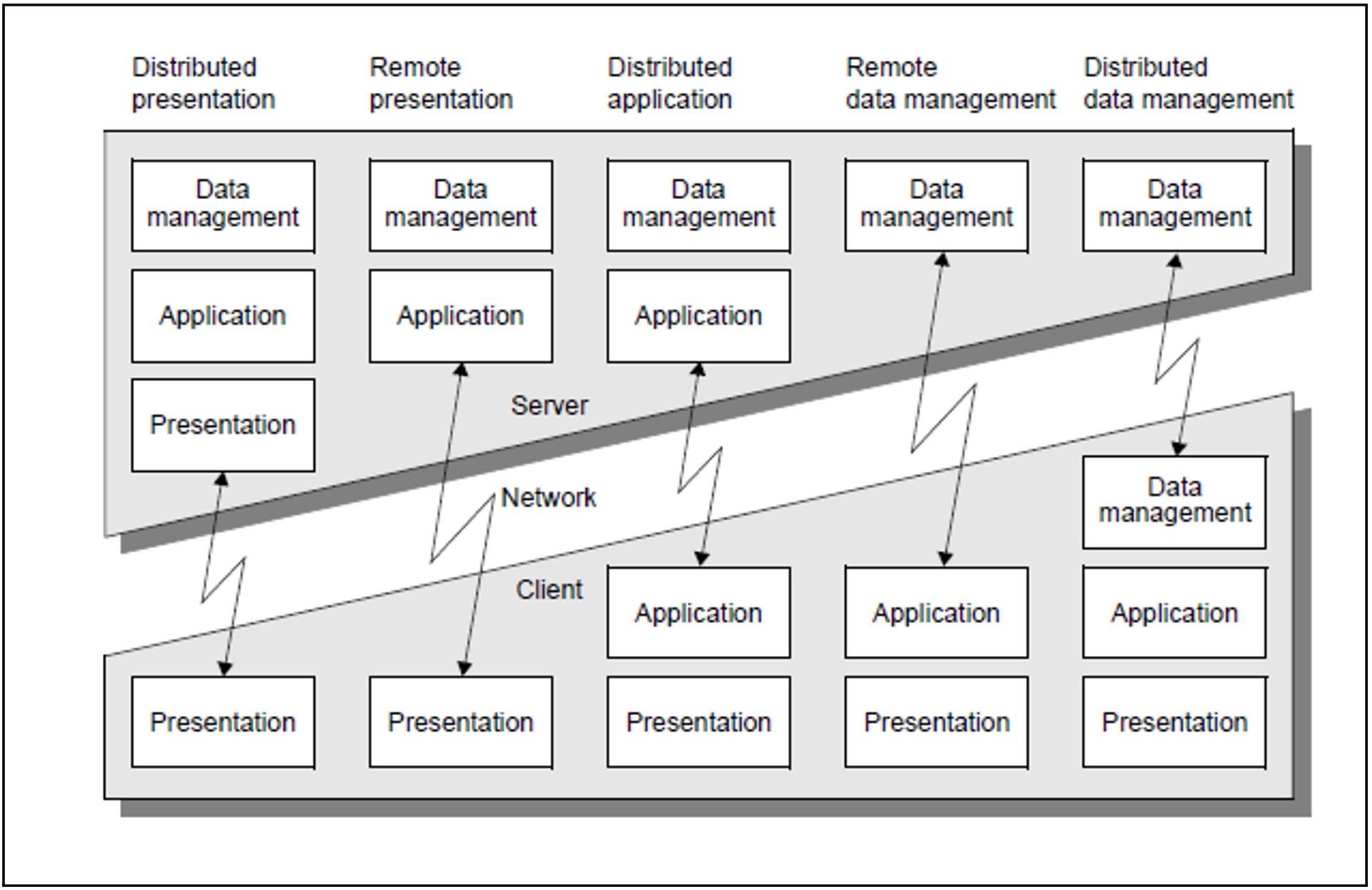
Figure 12: Basic model for client/server architectures
openUTM not only supports the basic model shown in figure 12, but also numerous other adaptations and combinations. It allows for complex multi-tier scenarios on the level of both physical and logical tiers.
As shown in figure 13 (on the next page), openUTM permits the distribution of data or application logic, as well as any combinations thereof. Data can thus be stored at the locations at which it is processed. Instead of transmitting large volumes of data via the network, only jobs and results are transferred. This minimizes the network load. openUTM also guarantees global data consistency at all times.
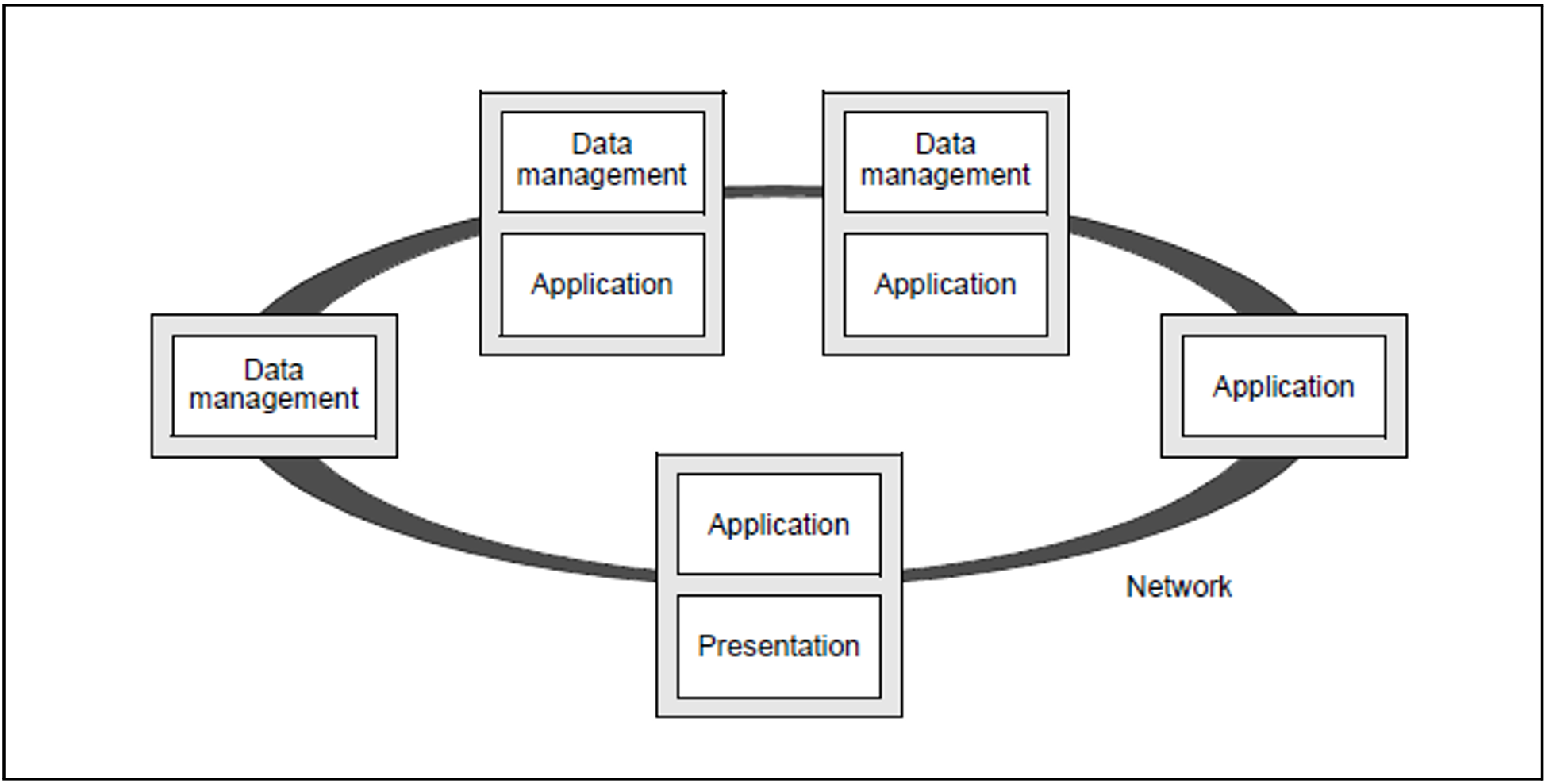
Figure 13: Multi-tier architecture
Disadvantages of conventional 2-tier architectures / advantages of multi-tier distribution
Many conventional client/server applications are based on a classic 2-tier architecture: the server is responsible for data management, while the client performs all other tasks if possible. However, this model has a number of disadvantages:
Since clients and servers usually communicate on an SQL level, unnecessarily large volumes of data frequently make round trips across the network. In configurations containing many users and when communicating via slow WAN links, the response times are simply unacceptable.
In this type of architecture, system maintenance is both time-consuming and expensive, since the application logic is implemented on the client systems. This inevitably results in redundancies and maintenance problems, particularly with large applications in heterogeneous environments. This is because each time the application logic is changed, you must perform follow-up maintenance on possibly several source program bases. Since the data model is at least partially visible on the clients, modifications to data management will invariably result in the need for adaptation of the client software.
Extensions to the application logic will increase the clients’ code and resource requirements. This can result in the fat client syndrome: the clients must be upgraded, and you may even have to switch over to a more powerful platform.
To avoid the problems outlined above, many database systems offer the option of relocating at least parts of the application logic to the server by means of stored procedures or trigger functions. This frequently involves the use of proprietary script languages which must be interpreted at runtime, resulting in performance bottlenecks. It is also possible to coordinate several database systems within a single transaction.
Multi-tier architectures based on openUTM allow you to overcome these restrictions and bottlenecks. The logical tiers “Presentation”, “Application” and “Data management” have clear physical boundaries and can be distributed arbitrarily. The network load is minimized, the system resources are relieved, and heterogeneous database systems and platforms can be coordinated. The system maintenance costs remain low. When extending the application, the resource requirement increases at only one central location or at a small number of central locations.