If different processing steps contain identical subtasks, it is advisable to split the individual processing steps into several parts. You write a separate program unit for each subtask and this can be used jointly by all processing steps. This is an exception to the basic rule for a service structure "one processing step = one program unit": here, one processing step is performed by multiple program units. This is achieved by using the PEND PR/PA/SP calls which terminate the program unit, but not the processing step. If you use PEND SP, a synchronization point is set. If you use PEND PA/PR, the transaction remains open.
In the following diagram, the two processes are single-step services, although each of them consists of three program unit runs:
The service to which the TAC1 transaction code is assigned changes the data of an insurance contract.
The service to which the TAC2 transaction code is assigned deletes the data of an insurance contract.
What is common to both services is that they have to change the initial data record. In order to create a separate program unit to perform this common task the processing step is split into individual parts.
After the INIT call the KCTACVG field contains the TAC which was used to start the service. The program unit "CENTRAL" then determines which program unit has to be used to continue the transaction. You have to specify the TAC of this program unit in the KCRN field for both MPUT as well as PEND PR. The MPUT message is not sent to the communication partner, but to the follow-up program unit where it is read using MGET. Since the processing step is not terminated in the program unit "CENTRAL", an MPUT call is not mandatory in this program unit: you may also transfer the data using service-specific storage areas instead of MPUT (see also section "KDCS storage areas in openUTM").
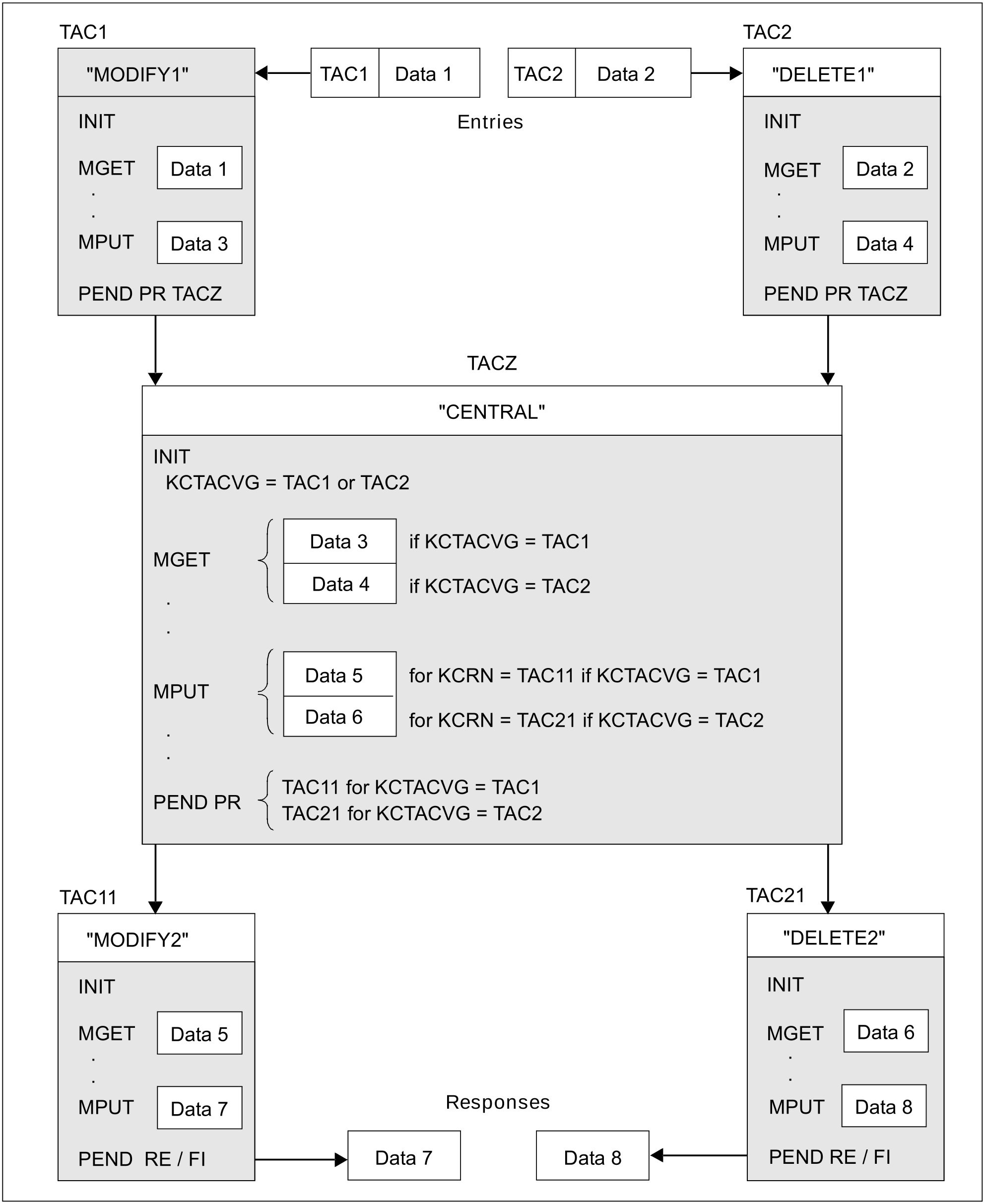
Figure: Multiple program units performing one processing step