In event logging events that occur in the whole Management Cluster are protocolled and shown to the administrator.
Example: The status changes of systems (for example the start of a BS2000-VM), starting a unit (SU, MU, HNC), the status changes of clusters (Management and SU Clusters).
All events in event logging are prioritized according to their meaning.
After assessing and processing (if needed), the current events should be acknowledged. This will cause them to disappear from the display of current events.
Hint: the current events cannot be acknowledged individually. They must be acknowledged in total.
The number of unacknowledged events as well as their priority is displayed in the Dashboard in their own tile.
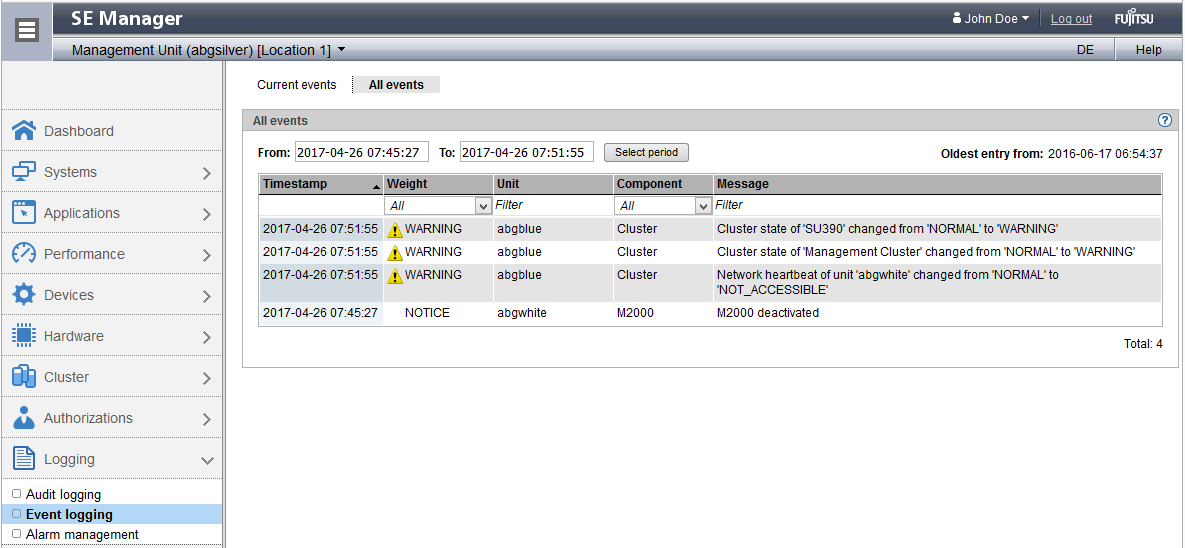
In the following example events can be seen in context (bottom-up):
- The MU abgwhite is powered down and reports itself as deactivated (component M2000)
- As the MU abgwhite does not answer to heartbeat queries, it is reported with the priority WARNING (component Cluster)
- As the functionality of the Management Cluster is affected by powering down the MU abgwhite (loss of redundancy), it is reported with the priority WARNING (component Cluster).
The status of the management cluster changes to WARNING as well. - As the functionality of the SU /390 Cluster is affected by powering down the MU, it is reported with priority WARNING (component Cluster).
The status of the SU /390 Cluster also changes itself to WARNING.
Further details can be found in the manual “Administration and Operation“ [1] and in the online help of the SE Manager.
The list of possible events can be found in an attachment (see “Further Information”) of the online help of the SE Manager.