Effects on database operation
If BCHECK accesses the original database during the check run, this is referred to as an online check run and can be executed in parallel with SHARED-RETRIEVAL database operation.
Check runs in which BCHECK does not access the original database are known as offline check runs and can be executed in parallel with any database operation mode.
More than one check run can be executed in parallel.
Before each BCHECK run, the database to be checked or the shadow database must be assigned with the following command:
/ADD-FILE-LINK LINK-NAME=DATABASE,FILE-NAME=dbname.DBDIR[.copy-name]
At startup BCHECK takes into account any assigned UDS/SQL pubset declaration (see the “Database Operation” manual, Pubset declaration job variable). Faulty assignment leads to the program aborting.
Coherence checking
During each check run, BCHECK performs a coherence check on the databases for which it can access the DBDIR. The following databases are checked for coherence:
For overall checking:
the original database or the shadow databaseFor incremental checking of original <-> shadow database:
the original database and the shadow database, provided its DBDIR is availableFor incremental checking of new shadow database <-> old shadow database: the newer shadow database and the older shadow database, provided its DBDIR is available
The following diagrams show the files needed for the various check runs:
Overall check of original
Original of each realm to be checked
Original of DBDIR
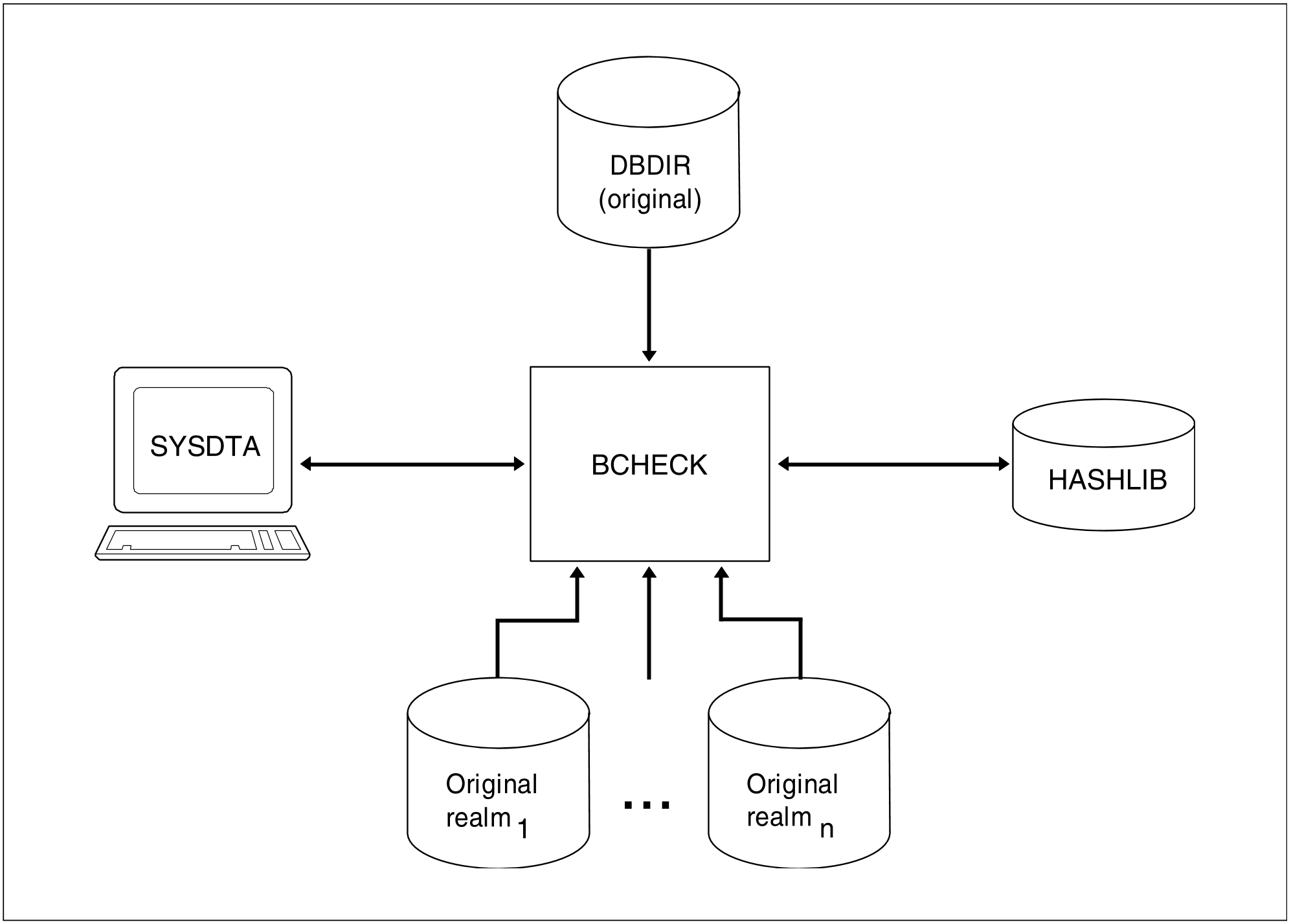
Figure 5: System environment for an overall check of original realms
Overall check of shadow database
Realms of the shadow database that are to be checked
DBDIR of the shadow database
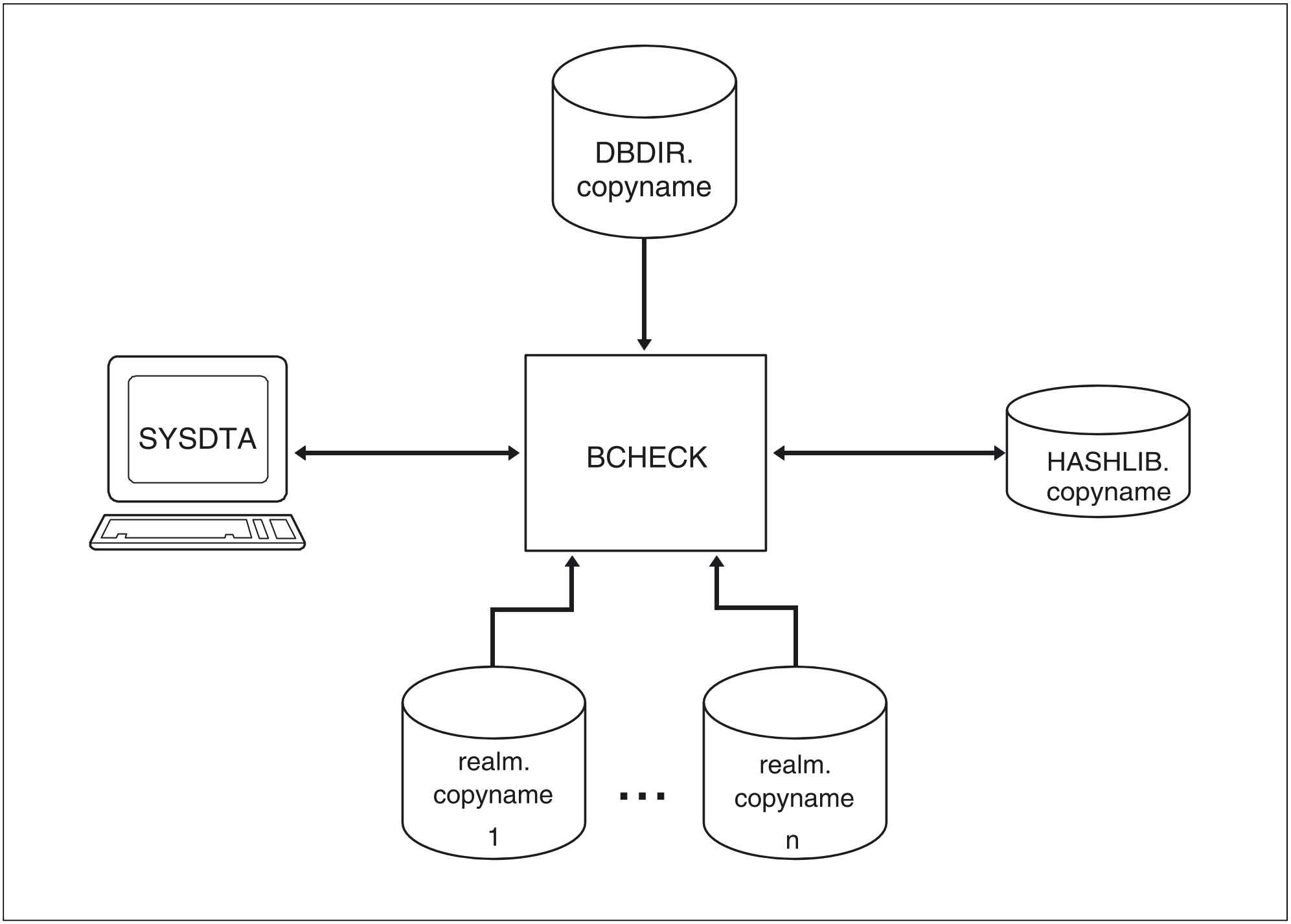
Figure 6: System environment for an overall check of the shadow database
Incremental check of original <-> shadow database
Original of each realm to be checked
Original of the DBDIR
Realms of the shadow database
Possibly, DBDIR of the shadow database (see "System environment")
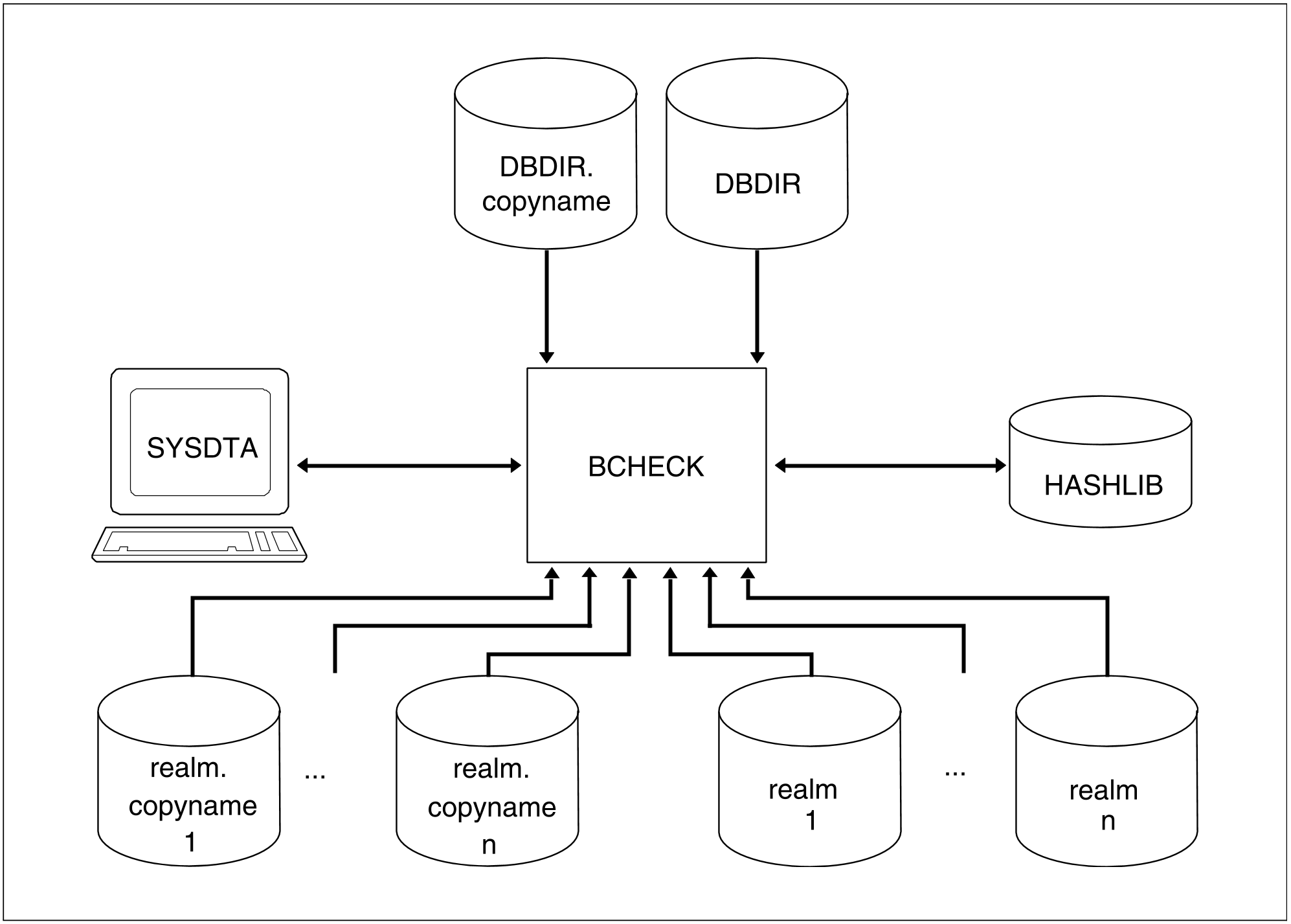
Figure 7: System environment for an incremental check of original <-> shadow database
Incremental check of new shadow database <-> old shadow database
Realms of each shadow database that are to be checked
DBDIR for older shadow database or both DBDIRs (see "System environment")
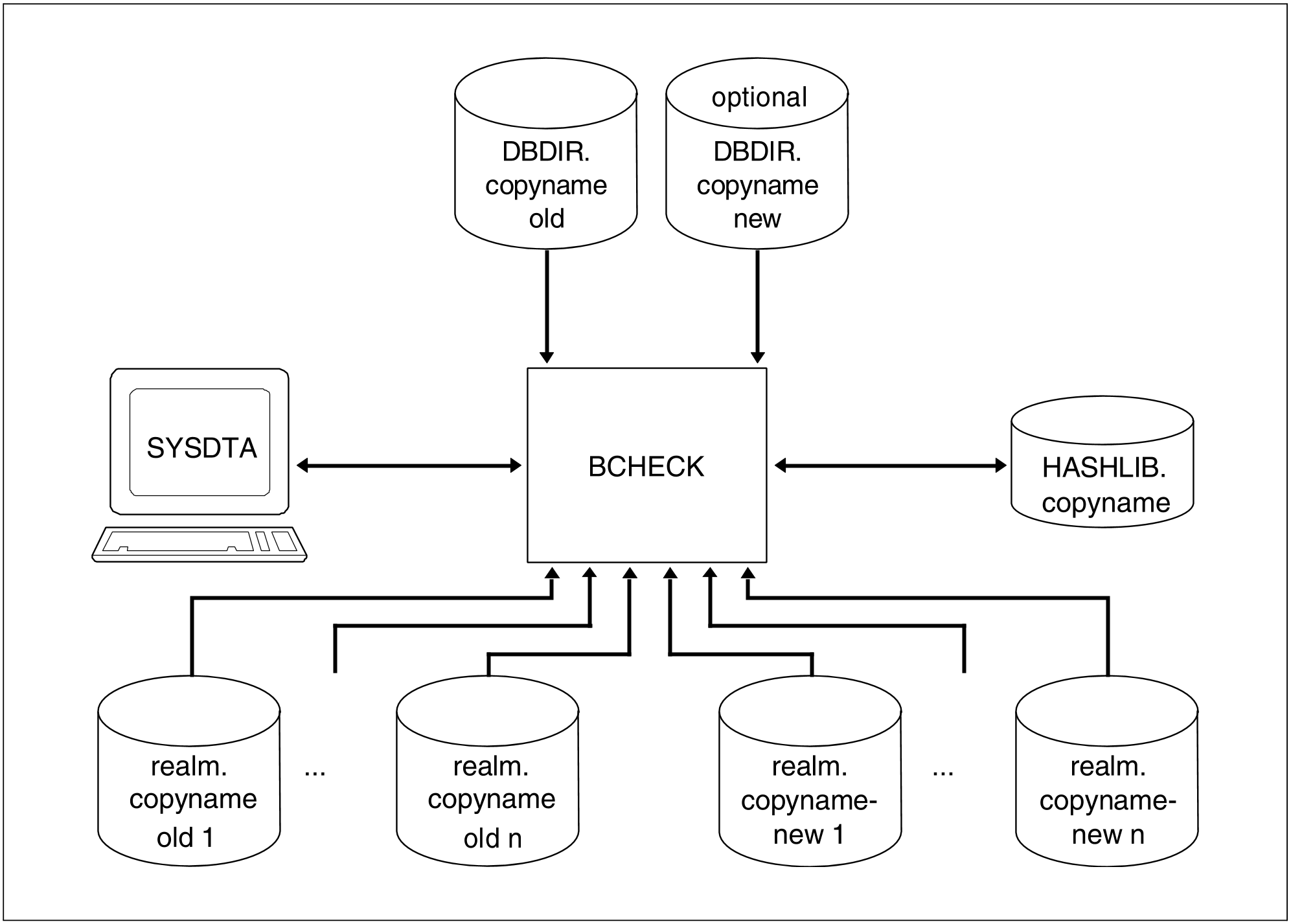
Figure 8: System environment for an incremental check of shadow database <-> shadow database
Required work files
BCHECK requires two work files for a check run which it sets up automatically on public disk under the user identification under which it was started and which it deletes again after the run has terminated normally. The default link names of these files are SCRTCH1 and SORTWK:
SCRTCH1
BCHECK requires this file during each check run to store a page directory.
SORTWK
Requires the SORT used by BCHECK in the case of a sort check and when checking index values in order to collate and sort the check records. See also the manual “SORT (BS2000)”.
If the two work files are to be created explicitly, they must be assigned the following attributes:
Work-file-1
File link name: SCRTCH1
Access method = SAM; fixed record length
The data population for buffering can be calculated using the following formula:
number-of-pages x 16 Bytes
number-of-pages
Number of relevant pages of all realms to be checked, i.e. the sum of the realm sizes in PAM pages minus the act-key-0 pages, FPA pages, and empty pages.
The primary allocation for Work-file-1 should be based on the data population that is to be buffered. There should always be an appropriate secondary allocation in case the storage space proves to be insufficient.
Work-file-2
File link name: SORTWK
Access method = PAM
In the case of an overall check, the data population for sorting can be calculated using the following two formulae
RSQ check formula:
26 x number-of-check-records BytesIndex value check and key value check formula:
key-length x number-of-check-records Bytes
You can ascertain the population involved in a SORTING run by first performing CHECK SUMMING, calculating twice the total amount of check objects from “RECORD/TABLE-OCCURRENCES, CHAIN-SET-MEMBERSHIPS, REFERENCES BETWEEN TABLE-OCCURRENCES and REFERENCES FROM TABLES TO MEMBER-RECORDS as given by DIAGNOSTIC SUMMARY OF BCHECK” and entering this value as number-of-check-records in the RSQ check formula.
When performing a SORTING run with key value checking, you add the value ascertained from the key value check formula to the value thus obtained, using double the value of USERKEYS BETWEEN TABLES AND MEMBER-RECORDS as number-of-check-records.
When performing a SORTING run with index value checking, you add the value ascertained from the index value check formula to the value obtained so far, using double the value of REFERENCES BETWEEN TABLE-OCCURRENCES as number-of-check-records.
As the key length you use the average key length of all keys (weighted with the number of records); in the case of the index value check for keys with duplicates you must take into account an additional 6 bytes. To simplify matters, you can use the maximum key length and, if duplicates are permitted, the additional 6 bytes to ensure that no resource bottleneck occurs when sorting takes place.
In the case of incremental checks, the population refers to the changes compared to the comparison state.
SORT needs Work-file-2 if the main memory affected by the SORTCORE statement is inadequate. The primary allocation should therefore be based on the data population that is to be sorted . There should always be an appropriate secondary allocation in case it is necessary to extend the storage space.