Primärindexblock
Ausgehend von den im Abschnitt „ISAM-Datenblock" beschriebenen Datenblöcken übernimmt das DVS für jeden Datenblock den jeweils höchsten Schlüssel, verknüpft mit der logischen Blocknummer des Datenblocks, in einen Primärindexblock. Bei NK-ISAM wird aus diesem Schlüssel ein „Separator“ gebildet, bei K-ISAM werden ggf. auch Wertmarkierung und logische Markierung in den Indexeintrag übernommen.
Jeder Primärindexblock entspricht genau einer PAM-Seite. Reicht ein Primärindexblock nicht aus für die Verweise auf alle Datenblöcke, wird nicht nur ein zweiter Primärindexblock auf der gleichen Ebene angelegt, sondern auch ein Primärindexblock auf einer zweiten Ebene, dessen Einträge auf die Primärindexblöcke der ersten Ebene verweisen. Auf diese Weise entsteht ein Primärindexbaum.
Primärindexbaum
Die Baumstruktur einer ISAM-Datei wird gebildet durch die Primärindex- und Datenblöcke. Die Datenblöcke bilden die unterste Ebene (Ebene 0). Die übrigen Ebenen bestehen nur aus Primärindexblöcken. Die höchste Ebene besteht nur aus einem einzigen Primärindexblock, der auch als „Wurzel“ des Primärindexbaums bezeichnet wird und den Einstiegspunkt bildet für alle Zugriffe auf Sätze einer ISAM-Datei.
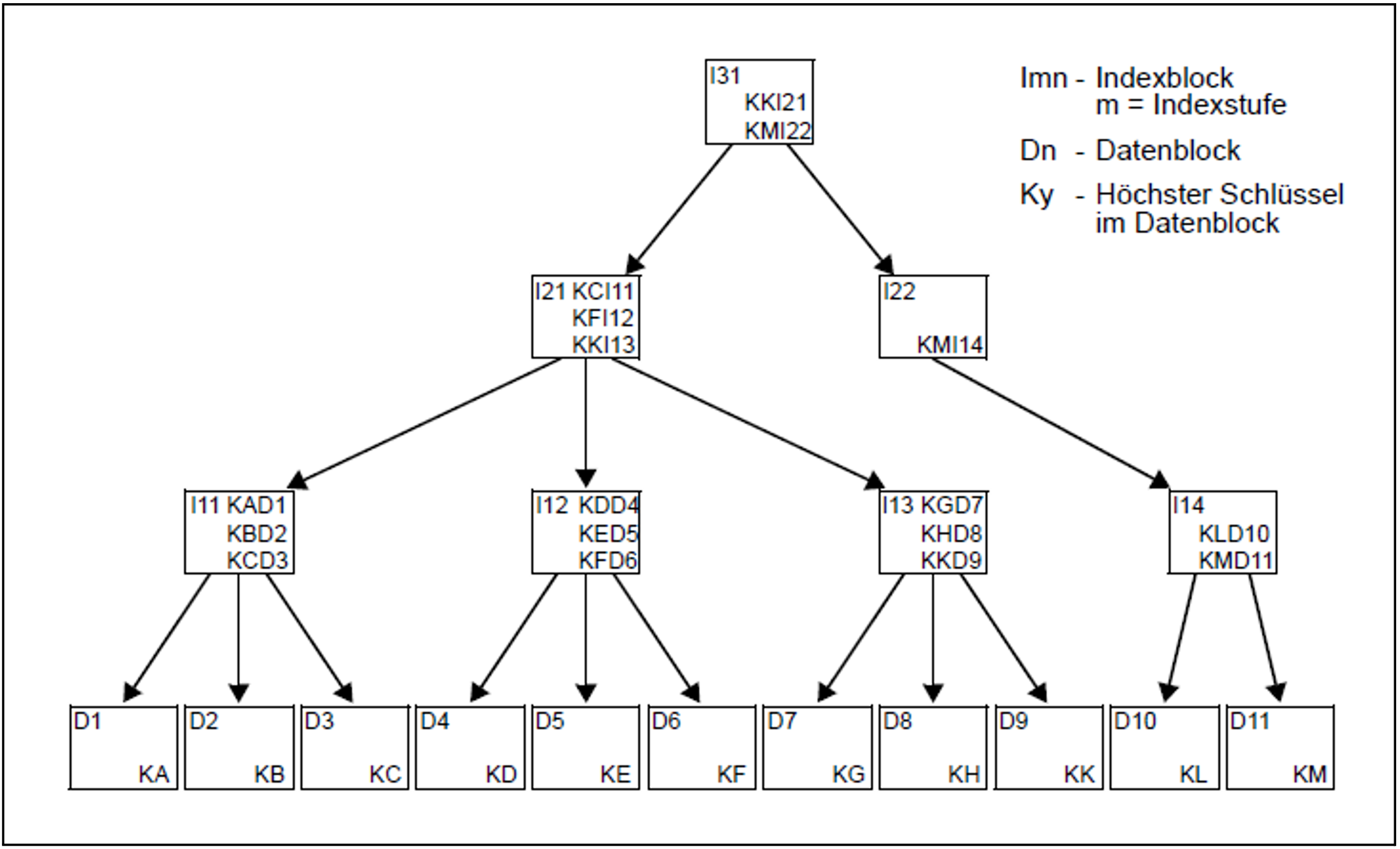
Die im Beispiel gezeigte K-ISAM-Datei hat drei Primärindexebenen (I1, I2, I3) und die Datenebene (D). Die Wurzel des Primärindexbaums ist hier der Primärindexblock I31. Die Buchstaben Ky stellen den jeweils höchsten Schlüssel im Datenblock dar. Diese Schlüssel werden mit einem Verweis auf den zugehörigen Datenblock in die Primärindexblöcke der Ebene I1 aufgenommen. Für jeden Primärindexblock I1n wird wieder der höchste vorkommende Schlüssel, diesmal mit Verweis auf den Primärindexblock, in einen Primärindexblock der Ebene I2 aufgenommen. Da auch in dieser zweiten Ebene ein Primärindexblock nicht ausreicht, um alle Einträge aufzunehmen, muss eine dritte Primärindexebene erzeugt werden (I3), die nur noch aus einem Primärindexblock besteht, der Wurzel.
Sekundärindexblock (NK-ISAM)
Zu jedem in der Datei definierten Sekundärschlüssel legt das DVS einen Sekundärindex aus einem oder mehreren Sekundärindexblöcken an. In ihm hinterlegt es für jeden in der Datei vorkommenden Wert dieses Sekundärschlüssels einen Eintrag, der den Primärschlüsselwert des zugehörigen Datensatzes als Verweis enthält. Einträge mit identischem Sekundärschlüsselwert werden zu einem Satz zusammmengefasst. Würde ein solcher Satz die Grenzen eines Sekundärindexblockes überschreiten, wird ein weiterer Satz zum gleichen Sekundärschlüsselwert gebildet.
Ein Satz in einem Sekundärindex besteht aus
dem Sekundärschlüsselwert mit dem größten Zeitstempel, der im Satz enthalten ist. Statt des Zeitstempels ist der Wert X'FF...FF' enthalten, wenn es sich um den letzten Satz mit dem Sekundärschlüsselwert handelt.
einem oder mehreren Einträgen: Jeder Eintrag besteht aus dem Primärschlüsselwert des betreffenden Datensatzes und einem Zeitstempel. Wenn für den Sekundärschlüssel mehrfach auftretende Werte nicht zugelassen sind (Angabe DUPKEY=NO im Makro CREAIX bzw. DUPLICATE-KEY=*NO im Kommando CREATE-ALTERNATE-INDEX), enthält jeder Satz nur einen Verweis und dessen Zeitstempel den höchstmöglichen Wert (X'FF...FF').
Für einen Satz im Sekundärindexblock zu einem bestimmten Sekundärschlüsselwert ergibt sich daraus folgender Aufbau:
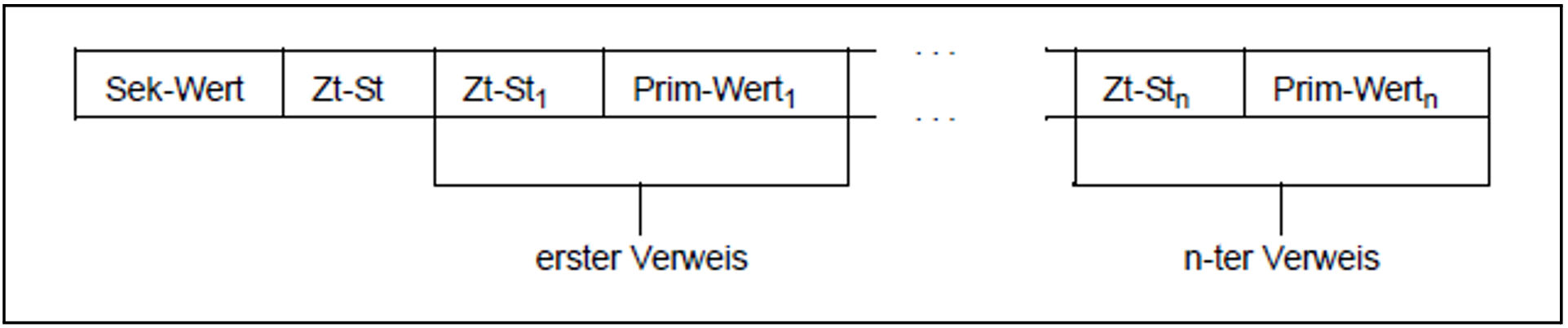
Im Bild bedeutet:
Sek-Wert | Sekundärschlüsselwert, für den dieser Satz angelegt wurde |
Zt-St | Zeitstempel des Satzes |
Zt-Sti | i=1,...,n: Zeitstempel des i-ten Eintrags |
Prim-Werti | i=1,...,n: Primärschlüsselwert des Datensatzes, auf den der i-te Verweis zeigt |
Zugriff auf Sätze in einer ISAM-Datei
Zugriff über den Primärschlüssel (ISAM-Schlüssel)
Wird eine ISAM-Datei nichtsequenziell verarbeitet, muss das DVS dem Benutzerprogramm den gewünschten Datensatz direkt zur Verfügung stellen können. Es beginnt mit der Suche nach einem Satz mit dem gewünschten Schlüssel immer in der obersten Primärindexebene – bei der Wurzel des Primärindexbaums – und wird dann (abwärts) durch alle Primärindexebenen bis zum benötigten Datenblock geführt. Die Suche innerhalb eines Primärindexblocks wird bei NK-ISAM dadurch beschleunigt, dass Primärindexeinträge zu „Sections“ zusammengefasst werden, sodass die Suche in Sprüngen verläuft.
Im Beispiel Bild 32 könnte z.B. der Satz mit dem Schlüssel KI gesucht werden. Aus den Primärindexeinträgen in I31 ist ersichtlich, dass die Suche im Primärindexblock I21 fortgesetzt werden muss: der Schlüssel KI ist kleiner als KK.
Die Einträge im Primärindexblock I21 verweisen für KI auf den Primärindexblock I13: KF < KI < KK.
Der Primärindexblock I13 enthält schließlich den Verweis auf den Datenblock D9: KH < KI < KK.
Der gesuchte Satz ist jetzt schnell zu finden.
Sowohl bei NK-ISAM als auch bei K-ISAM sind die Zugriffspfade über eine Baumstruktur realisiert, bei K-ISAM enthält der Primärindexblock der höchsten Stufe allerdings noch einen 36 Bytes langen Header mit Verwaltungsinformationen, bei NK-ISAM sind die Verwaltungsinformationen im Kontrollblock zu finden.
Durch die Schlüsselkomprimierung in den Primärindexblöcken ist bei NK-ISAM die Länge eines Primärindexeintrags nahezu unabhängig von der Schlüssellänge. Damit hängt die Zahl der Primärindexeinträge und -stufen nur noch von der Zahl der Datenblöcke ab.
Bei K-ISAM sind die Anzahl der Primärindexblöcke und der Primärindexebenen einer ISAM-Datei nicht nur abhängig von der Zahl der Datenblöcke, sondern auch von der Länge des ISAM-Schlüssels, bzw. von der Länge des ISAM-Primärindex, wenn Wert- oder logische Markierung genützt werden: es erfolgt keine Schlüsselkomprimierung, bei einer Primärindexlänge von 255 Bytes enthält ein Primärindexblock also nur 4 Indexeinträge.
Zugriff über einen Sekundärschlüssel (NK-ISAM)
Wenn Sie einen Datensatz über den Wert eines Sekundärschlüssels anfordern, so sucht das DVS zunächst in den zugehörigen Sekundärindexblöcken nach einem Satz mit diesem Wert. Ist ein solcher Satz vorhanden, so ermittelt es aus den darin enthaltenen Einträgen den Primärschlüsselwert des gewünschten Datensatzes. Bei mehreren Einträgen im Satz (mehrfach auftretende Sekundärschlüsselwerte) wählt es stets den Ersten aus. Mit diesem Primärschlüsselwert sucht das DVS dann den angeforderten Datensatz wie im vorhergehenden Abschnitt beschrieben.
Die Suche eines Datensatzes über einen Sekundärschlüssel ist demnach aufwändiger als seine Bereitstellung über den Primärschlüssel: Es werden etwa doppelt so viele Ein-/Ausgaben und die doppelte CPU-Zeit benötigt.