Entsprechend der an die Dateiverarbeitung angelehnten Beschreibung von XML-Dokumenten erfolgt auch die Verarbeitung von XML-Dokumenten mit Hilfe der leicht erweiterten Anweisungen für Dateiverarbeitung:
OPEN DOCUMENT:
Beginn der Verarbeitung eines XML-(Teil-)Dokuments, sowie Zuordnen einer Satzbeschreibung aus der FD des XML-Dokuments zu einem Dokument in BaumdarstellungSTART ATTRIBUTE bzw. START ELEMENT:
Positionieren im Baum, ausgehend von einer bereits zugeordneten SatzbeschreibungREAD ATTRIBUTE bzw. READ ELEMENT:
Übertragen von Daten aus dem Baum in entsprechende Datenfelder der zugeordneten SatzbeschreibungCLOSE DOCUMENT:
Ende der Verarbeitung eines XML-(Teil-)Dokuments
Die Fehlerbehandlung ist wie bei der Dateiverarbeitung über anweisungsspezifische Angaben (AT END, INVALID KEY) bzw. über USE-Anweisungen möglich. Das Datenfeld der FILE STATUS-Klausel beschreibt das Ergebnis der Anweisung, wobei neben den bisher schon definierten Werten neue XML-spezifische Werte möglich sind.
Bei der Verarbeitung eines XML-Dokuments ist für das Verständnis der Anweisungen wesentlich:
Knoten aus dem Baum werden den Datenfeldern einer Satzbeschreibung zugeordnet, die eine IDENTIFIED-Klausel haben.
Die aktuelle Zuordnung wird festgehalten.
Die aktuelle Zuordnung wirkt auf nachfolgende Anweisungen.
Die aktuelle Zuordnung kann durch Anweisungen geändert werden.
Element-Positions-Vektor (EPV)
Die Zuordnung von Knoten im Baum zu ihrer Beschreibung im COBOL-Programm wird mit Hilfe des Element-Positions-Vektor festgehalten. Der Name entspricht dem im Technical Report "Native COBOL Syntax for XML Support" verwendeten 'Element Position Vector' – er dient jedoch der Zuordnung aller Knoten, Element- und Attribut-Knoten. Es handelt sich dabei um eine interne Verwaltungsstruktur des COBOL-Systems für die Verarbeitung eines XML-Dokuments: Jeder im Programm beschriebene Knoten (d.h. nur Datenfelder mit einer IDENTIFIED-Klausel) hat einen Eintrag im EPV. In diesem Eintrag ist die Position eines aktuell zugeordneten Knotens aus dem Baum gespeichert – dieser Zustand wird im Folgenden auch mit ’das Datenfeld hat eine Position' bezeichnet.
Wenn einem Datenfeld noch kein Knoten zugeordnet wurde, oder wenn die Zuordnung durch eine Anweisung ungültig geworden ist, wird auch dieser spezielle Zustand im EPV vermerkt. Die Interpretation der gespeicherten Positionen durch nachfolgende Anweisungen hängt außerdem davon ab, ob sie als Resultat einer READ- oder einer OPEN- bzw. START-Anweisung entstanden sind.
Zudem kann ein Datenfeld nur dann eine gültige Position haben, wenn alle ihm in der Struktur übergeordneten Datenfelder auch eine gültige Position haben.
Zuordnen von Knoten
Eine Zuordnung modifiziert nur den EPV, überträgt aber keine Daten.
Voraussetzung für das Zuordnen eines Knotens aus dem Baum zu einem Datenfeld
Die gleiche Art des Knotens im Baum und in der IDENTIFIED-Klausel des Datenfeldes, d.h. beide sind Element-Knoten bzw. beide Attribut-Knoten.
Die ’Übereinstimmung’ des in der IDENTIFIED-Klausel angegebenen Namens mit dem Namen des Knoten im Baum:
Bei einer BY-Angabe müssen die Namen identisch sein, abgesehen von endständigen Leerzeichen.
Bei einer USING-Angabe wird jeder beliebige Name aus dem Baum als übereinstimmend angesehen.
Zuordnungsvorgang
|
Beispiel 12-39 Prinzip der Zuordnung von Knoten
XML-Dokument | Knoten-Position | COBOL-Datenstruktur | EPV |
| 1 2 3 4 5 6 |
| inv inv 1 3 inv 2 |
Anmerkungen:
Datenfelder für Werte spielen bei der Zuordnung keine Rolle. Sie sind daher in der COBOL-Beschreibung weggelassen.
Annahme für den ersten Schritt: Auf COBOL-Seite werden die Datenfelder auf Stufe 01 (x und z) betrachtet, auf XML-Seite nur der Knoten1 – das entspricht dem Verhalten einer OPEN DOCUMENT-Anweisung, siehe auch "OPEN DOCUMENT". Für die Zuordnung des XML-Dokuments zur COBOL-Beschreibung muss ein Datenfeld gefunden werden, das den Namen des Wurzel-Knotens 'a' in seiner IDENTIFIED-Klausel angibt: das ist das Datenfeld z.
In den folgenden Schritten wird die Zuordnung anschließend fortgesetzt auf Seite des Baums mit den Kindern des soeben zugeordneten Knoten 1 - beginnend bei dem ältesten, d.h. mit den Knoten 2, 3, 4 und 6. Auf der Seite der COBOL-Beschreibung kommen dafür entsprechend nur die Datenfelder mit einer IDENTIFIED-Klausel in Frage, die dem Datenfeld, dem gerade der Vaterknoten zugeordnet wurde, direkt untergeordnet sind, d.h. die dem Datenfeldz untergeordneten Datenfelder u und w.
Dem Datenfeldu kann Knoten 3 mit Namen 'b' zugeordnet werden, dem Datenfeld w kann Knoten 2 mit Namen 'd' zugeordnet werden.
Knoten 4, ebenfalls mit Namen 'b', kann nicht zugeordnet werden: Im Prinzip käme das Datenfeldu dafür in Frage, aber u steht nicht mehr zur Verfügung, da ihm bereits der Knoten 3 zugeordnet wurde. Da Knoten 4 nicht zugeordnet werden kann, kommen auch alle seine Kinder, deren Kinder usw. – hier nur der Knoten 5 – für weitere Zuordnungen nicht in Frage.
Knoten 6 kann ebenfalls nicht zugeordnet werden, da keines der dem Datenfeld z direkt untergeordneten Datenfelder (u, w) in seiner IDENTIFIED-Klausel den Namen 'c' angibt. Datenfeld y gibt zwar den passende Namen an, gehört aber nicht zu den betrachteten Datenfeldern, weil es kein Kind von Datenfeld z ist.
Nachdem Datenfeld u der Knoten 3 zugeordnet wurde, kommen auch die dem Datenfeldu direkt untergeordneten Datenfelder (v) für Zuordnungen in Frage. Da aber der zugeordnete Knoten 3 keine Kinder hat, sind auch keine weiteren Zuordnungen möglich.
Im letzten Schritt bekommen alle während des Verfahrens betrachteten Datenfelder, denen keine Knoten zugeordnet werden konnten, ungültige Positionen: das sind aus dem ersten Schritt das Datenfeld x mit seinem untergeordneten Datenfeldy und aus den folgenden Schritten das Datenfeld v.
Das Verfahren für die Zuordnung von Knoten bedeutet:
Die Reihenfolge von zugeordneten Geschwister-Knoten im Baum muss nicht mit der Reihenfolge übereinstimmen, in der sie in der COBOL-Datenstruktur beschrieben sind.
Die Hierarchie der Datenfelder in der COBOL-Beschreibung entspricht direkt der Hierarchie der zugeordneten Knoten im Baum. Es gibt keine Lücken. Für die Knoten bedeutet dies: Wenn ein Knoten aus dem Baum einem Datenfeld zugeordnet ist, ist auch sein Vater einem Datenfeld der COBOL-Struktur zugeordnet.
Bei mehreren 01-Strukturen in einer FD kann es immer nur in einer einzigen 01-Struktur gültige Positionen geben.
Ziel ist es, nicht so viele Zuordnungen wie möglich zu Stande zu bringen, sondern die Zuordnungen immer in einer gleichen festen Reihenfolge vorzunehmen.
Anweisungssequenzen
In den folgenden Abschnitten werden die wesentlichen Wirkungen der Anweisungen kurz dargestellt, jedoch ohne Details der Syntax und aller Regeln.
Für jede Themengruppe wird zunächst ein Mindestmaß an Information angeboten, das aufzeigt, wie die Anweisungen prinzipiell funktionieren. Dies wird dann anhand von Beispielen mit Anmerkungen veranschaulicht. Abschließend werden pro Themengruppe wichtige Informationen zusammengefasst, jedoch ohne Anspruch auf Vollständigkeit. Um alle Informationen zu einem Thema gebündelt nachzulesen, sichten Sie die entsprechenden Abschnitte im Kapitel "XML" .
Die Anweisungen zur Verarbeitung des XML-Dokuments bzw. einzelner Teile davon müssen die in der nachfolgenden Abbildung dargestellten Reihenfolgen einhalten. Weitere COBOL-Anweisungen zur eigentlichen Verarbeitung der XML-Daten sind der Übersichtlichkeit halber weggelassen.
{} | | kennzeichnen wiederholbare Einzelschritte trennt mögliche Alternativen |
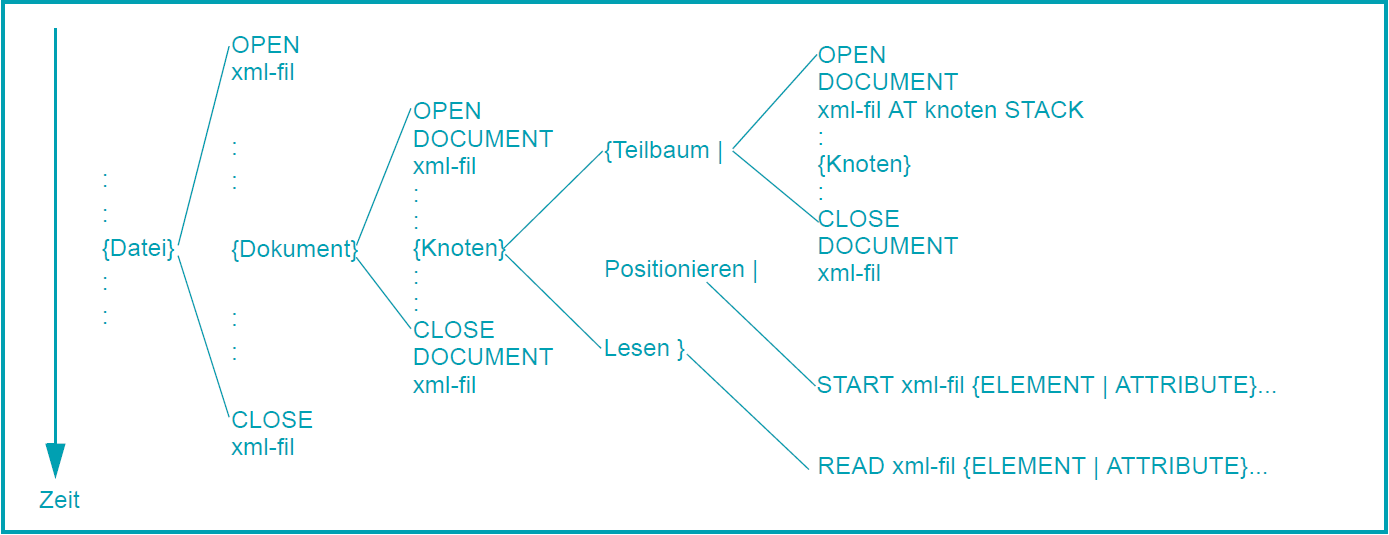
Der Übersichtlichkeit halber verzichtet die Darstellung der neuen Anweisungen weitgehend auf mögliche Fehlersituationen und deren Behandlung. Der Überblick zu Fehlerfällen folgt in Abschnitt "Fehlerbehandlung".
Wichtige Hinweise zur Darstellung der nachfolgenden Beispiele 12-40 bis 12-56:
Von links nach rechts wird in den Spalten der Beispieltabellen jeweils Folgendes dargestellt:
- XML-Dokument:
Die XML-Dokumente sind auf das für den Beispielzweck Wesentliche reduziert. Sie sollten nicht als wohlgeformtes XML missverstanden werden.
Zusätzlich sind die XML-Dokumente der besseren Lesbarkeit halber mit Einrückungen/Leerzeichen und Zeilenwechseln versehen. Diese Editierungen sind nicht als Teil der Werte eines Knotens gemeint.
- Positionen, die den XML-Knoten entsprechen
- COBOL-Beschreibung
Anschließend folgen spaltenweise die nacheinander ausgeführten Anweisungen. Dabei ist jeweils der Zustand nach Ausführung der Anweisung festgehalten: Ein im EPV zugeordneter Knoten (d.h. seine Position) ist dazu bei der IDENTIFIED-Klausel vermerkt. In Klammern wird angefügt, durch welche Anweisung die Position entstanden ist:
o
OPEN DOCUMENT, START
r
READ
Alle als Folge der Anweisung modifizierten Positionen und Inhalte sind in der zugehörigen Spalte fett dargestellt, alle unveränderten Werte kursiv.
Für den Einzelfall unwichtige Anweisungen und Definitionen sind weggelassen.