Daten sollten so maschinenunabhängig wie möglich beschrieben sein. Um dies zu erreichen, werden die Charakteristika und Eigenschaften der Daten in einem Format beschrieben, das weitgehend unabhängig ist von der konkreten Darstellung im Computer oder auf dem externen Datenträger.
Für Literale gilt:
Der Inhalt alphanumerischer nicht-hexadezimaler Literale wird für die Ablaufzeit unverändert übernommen.
Der Inhalt nationaler nicht-hexadezimaler Literale wird für die Ablaufzeit immer zu UTF-16-Darstellung konvertiert.
Hexadezimale Literale geben immer das endgültige, zur Ablaufzeit zu verwendende Bitmuster an.
1. Konzept des logischen Satzes und der Datei
Die logischen Eigenschaften eines Satzes oder einer Datei unterscheiden sich von der Art und Weise, wie Daten in der Datenverarbeitungsanlage physisch abgespeichert werden.
Physische Eigenschaften einer Datei
Die physischen Eigenschaften einer Datei ergeben sich aus der Art und Weise, wie die Daten auf dem Eingabe- oder Ausgabemedium gespeichert sind, und umfassen Angaben wie
die Gruppierung der logischen Sätze unter Berücksichtigung der physischen Grenzen des Speichermediums,
die Art, wie eine Datei identifiziert werden kann.
Logische Eigenschaften einer Datei
Die logischen Eigenschaften einer Datei ergeben sich aus den Strukturen, die der Benutzer durch Datendefinitionen festlegt. Die Ein-/Ausgabe-Anweisungen in einem COBOL-Programm beziehen sich auf logische Sätze.
Es ist äußerst wichtig, zwischen einem physischen Satz und einem logischen Satz zu unterscheiden.
Ein physischer Datensatz (oder Block) ist eine Informationseinheit, deren Größe und Satzmodus zum Speichern von Daten auf einem Ein- oder Ausgabedatenträger für eine bestimmte Datenverarbeitungsanlage vorteilhaft ist. Die Größe eines physischen Datensatzes ist maschinenorientiert und gestattet keinen direkten Vergleich zu der Größe der logischen Dateiinformation.
Ein logischer Datensatz (oder nur Datensatz) ist eine Gruppe von zusammengehörigen Daten, die eindeutig bezeichnet und als Einheit behandelt werden kann sowie aus einer Datei gelesen oder in eine Datei geschrieben werden kann. Mehrere Datensätze können in einem einzelnen Block enthalten sein.
Der Begriff Datensatz ist nicht beschränkt auf Daten, die auf einem externen Datenträger gespeichert sind, sondern ist übertragbar auf die Definition des Arbeitsspeichers für die Daten, die intern während des Programmablaufs erzeugt werden.
In dieser Beschreibung bedeuten Bezüge auf Datensätze immer Bezüge auf logische Datensätze.
2. Stufenkonzept
Das Stufenkonzept erlaubt die Strukturierung eines logischen Datensatzes. Daten, die von einem COBOL-Programm verarbeitet werden müssen, werden als Datenelemente, Datengruppen, Datensätze und Dateien beschrieben.
Datenelemente
Ein Datenelement ist die kleinste benannte Dateneinheit; d.h. ihm sind keine weiteren Datenelemente untergeordnet. Ein Datenelement wird meistens mit der PICTURE-Klausel beschrieben.
Zu Ausnahmen siehe Abschnitt „Formate der Datenerklärung".Die Länge eines Datenelements darf 131 071 Bytes nicht überschreiten.
Datengruppen
Mehrere Datenelemente werden zu einer Datengruppe zusammengefasst. So kann eine Anzahl von Datenelementen unter dem Namen der Datengruppe auf einmal angesprochen werden. Eine Datengruppe besteht somit aus einem oder mehreren Datenelementen. Sie darf aber auch weitere Datengruppen enthalten. Infolgedessen kann ein Datenelement zu mehr als einer Datengruppe gehören (siehe Bild 1 und Bild 2). Der Name einer Datengruppe darf nicht mit der PICTURE-Klausel beschrieben sein.Datensätze
Ein Datensatz ist ein Datenfeld, das keinem anderen untergeordnet ist. Ein Datensatz besteht aus einer Datengruppe oder ist selbst ein Datenelement. Die Beschreibung eines Datensatzes steht im Programmtext-Bereich.Stufennummern
Daten werden in verschiedene Stufen gegliedert. Diese Stufen werden durch Stufennummern bezeichnet. Zugelassen sind die Stufennumern 01 bis 49. Daneben gibt es die speziellen Stufennummern 66, 77 und 88. In einer Übersetzungseinheit muss für jede Stufennummer eine gesonderte Eintragung erfolgen.
Da ein Datensatz die größte Ordnungseinheit darstellt, beginnen die Stufennummern für Datensätze mit 01. Den hierarchisch untergeordneten Feldern werden zahlenmäßig höhere Stufennummern (02 bis 49) zugewiesen. Die Stufennummer eines untergeordneten Datenfeldes muss um eine oder mehrere Einheiten größer als die des übergeordneten Datenfeldes sein. Nach der Beschreibung eines Datenelementes ist nur eine Stufennummer zulässig, die in derselben Datensatzbeschreibung schon einmal aufgetreten ist.
Beispiel 2-8
Richtig:
Falsch:
01 DATENSATZ. 05 DATENGRUPPE-1. 10 DATENELEMENT-11 ... 10 DATENELEMENT-12 ... 10 DATENELEMENT-13 ... 05 DATENGRUPPE-2. 10 DATENELEMENT-21 ... 10 DATENELEMENT-22 ...01 DATENSATZ. 05 DATENGRUPPE-1. 10 DATENELEMENT-11 ... 10 DATENELEMENT-12 ... 10 DATENELEMENT-13 ... 03 DATENGRUPPE-2. 10 DATENELEMENT-21 ... 10 DATENELEMENT-22 ...Drei Arten von Daten, für die kein Stufenkonzept vorhanden ist, werden den Stufennummern 66, 77 und 88 zugeordnet:
Die Stufennummer 66 für Namen der Datenfelder, die mit der RENAMES-Klausel beschrieben sind (siehe Abschnitt „RENAMES-Klausel").
Die Stufennummer 77 für strukturunabhängige Datenfelder der
WORKING-STORAGE SECTION bzw. LINKAGE SECTION (siehe Abschnitt „Stufennummer").Die Stufennummer 88 für die Erklärung von Bedingungsnamen (siehe Abschnitt „VALUE-Klausel")
Weitere Regeln sind unter „Stufennummer“ ( Abschnitt „Stufennummer") beschrieben.
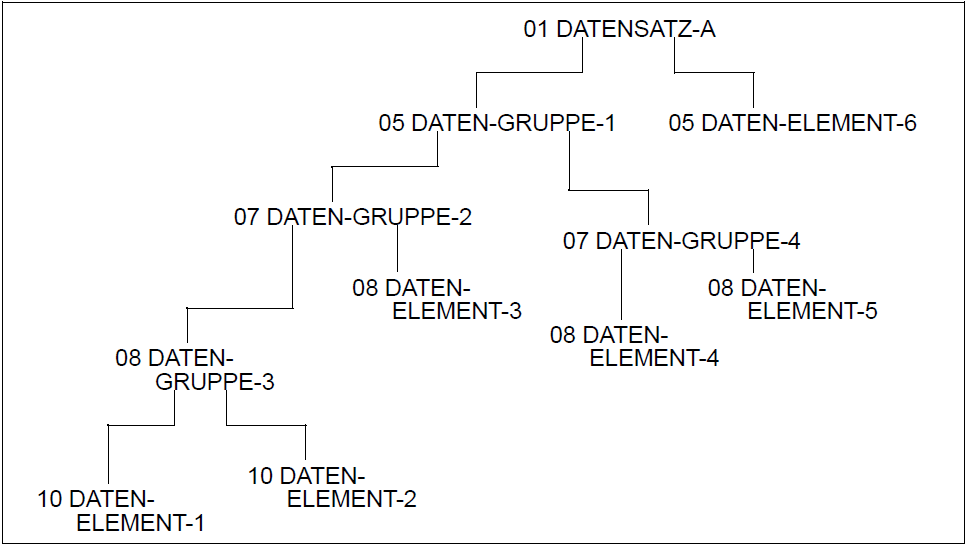
Bild 1: Beziehungen von Datengruppen und Datenelementen in einem Datensatz
01 DATENSATZ-A. 05 DATEN-GRUPPE-1. 07 DATEN-GRUPPE-2. 08 DATEN-GRUPPE-3. 10 DATEN-ELEMENT-1... 10 DATEN-ELEMENT-2... 08 DATEN-ELEMENT-3... 07 DATEN-GRUPPE-4. 08 DATEN-ELEMENT-4... 08 DATEN-ELEMENT-5... 05 DATEN-ELEMENT-6...Bild 2: Datengruppen und Datenelemente in einem Datensatz
Bild 1 zeigt die Struktur eines Musterdatensatzes und Bild 2 veranschaulicht, wie die Stufennummern zu verwenden sind, um diese Struktur in der Beschreibung des Datensatzes wiederzugeben. In diesem Beispiel sind DATEN-GRUPPE-3 und DATEN-ELEMENT-3 Teil von DATEN-GRUPPE-2 sowie DATEN-GRUPPE-2 und DATEN-GRUPPE-4 Teil von DATEN-GRUPPE-1.
3. Klassen und Kategorien von Daten und Literalen
Jedem Datenfeld und Literal ist eine Klasse und Kategorie zugeordnet.
Die Klasse und Kategorie einer stark typisierten Datengruppe ist der Typname, der in der TYPE-Klausel der Datengruppe angegeben ist.
Die Klasse und Kategorie einer nicht stark typisierten Datengruppe sind
alphanumerisch für eine alphanumerische Gruppe
national für eine nationale Gruppe
Eine alphanumerische Gruppe wird behandelt, als ob sie USAGE DISPLAY hat.
Die Klasse und Kategorie einer Funktion wird durch den Typ der Funktion festgelegt (siehe „Funktionstypen" im Abschnitt "Allgemeines").
Die Kategorie eines Datenelements hängt von seiner Beschreibung ab.
Die Klassen und Kategorien von Literalen sind im Abschnitt „Literale" definiert.Die nachfolgende Tabelle 7 veranschaulicht die Beziehungen von Klassen und Kategorien von Datenelementen.
Klasse
Kategorie
alphabetisch
alphabetisch
alphanumerisch
numerisch druckaufbereitetalphanumerisch druckaufbereitetalphanumerisch
index
index
national
national
numerisch
numerisch
objekt
objektreferenz
zeiger
datenzeigerprogrammzeiger
Tabelle 7: Klassen und Kategorien von Datenelementen
Die folgenden Abschnitte beschreiben die Datenfelder in den verschiedenen Kategorien.
Alphabetische Datenfelder
Ein alphabetisches Datenfeld ist ein Datenfeld, dessen Inhalt eine beliebige Kombination der 52 Groß- und Kleinbuchstaben des Alphabets und des Leerzeichens sein kann. Jedes alphabetische Zeichen ist in einem eigenen Byte des Arbeitsspeichers gespeichert.
Die Maskenzeichenfolge für alphabetische Datenfelder enthält nur das Symbol A.Das Datenformat von alphabetischen Datenfeldern ist immer DISPLAY.
Ein alphabetisches Datenfeld darf überall dort angegeben werden, wo ein alphanumerisches Datenelement als Operand zulässig ist. Sofern nicht anders angegeben, wird es behandelt, als ob es ein alphanumerisches Datenfeld wäre.
Alphanumerisch druckaufbereitete Datenfelder
Ein alphanumerisch druckaufbereitetes Datenfeld beschreibt die Form der Druckaufbereitung eines alphanumerischen Wertes. Falls ein alphanumerisch druckaufbereitetes Datenfeld ein Empfangsdatenfeld einer MOVE-Anweisung ist, werden die in das Datenfeld übertragenen Daten entsprechend der angegebenen Maskenzeichenfolge druckaufbereitet.
Seine Maskenzeichenfolge ist auf bestimmte Kombinationen der Zeichen A, X, 9,0 (Null), B und / (Schrägstrich) beschränkt (siehe Abschnitt „PICTURE-Klausel").
Die Inhalte eines alphanumerisch druckaufbereiteten Datenfeldes sind aus dem EBCDIC-Zeichensatz ausgewählte, zulässige Zeichen.Das Datenformat eines alphanumerisch druckaufbereiteten Datenfeldes ist immer DISPLAY.
Alphanumerische Datenfelder
Ein alphanumerisches Datenfeld ist ein Datenfeld, dessen Inhalt ein beliebiges Zeichen aus dem EBCDIC-Zeichensatz sein kann.
Die Maskenzeichenfolge eines alphanumerischen Datenfeldes ist auf eine Mischung der Zeichen A, X und 9 beschränkt. Das Datenfeld wird behandelt, als ob in seiner Maskenzeichenfolge nur die Zeichen X wären.
Eine Maskenzeichenfolge, die nur die Zeichen A oder nur die Zeichen 9 enthält, erklärt kein alphanumerisches Datenfeld. Das Datenformat eines alphanumerischen Datenfeldes ist immer DISPLAY.
Datenzeiger
Ein Datenzeiger (auch kurz nur Zeiger) ist ein Datenelement, in dem eine Datenadresse gespeichert werden kann.
Index Datenfelder
Jedes der folgenden ist ein Index Datenfeld:
ein Datenelement, das explizit oder implizit mit USAGE INDEX beschrieben ist
eine index Funktion
Nationale Datenfelder
Jedes der folgenden ist ein nationales Datenfeld:
ein Datenelement, das durch seine PICTURE Maskenzeichenfolge als national beschrieben ist
ein Datenelement ohne PICTURE-Klausel, das mit einer VALUE-Klausel des Formats 1 und einem nationalen Literal beschrieben ist
ein Datenelement, das explizit oder implizit mit USAGE NATIONAL beschrieben ist
eine Datengruppe, die explizit oder implizit mit einer GROUP-USAGE NATIONAL Klausel beschrieben ist
eine nationale Funktion
Numerisch druckaufbereitete Datenfelder
Ein numerisch druckaufbereitetes Datenfeld beschreibt die Form der Druckaufbereitung eines numerischen Wertes. Falls ein numerisch druckaufbereitetes Datenfeld ein Empfangsdatenfeld einer MOVE-Anweisung ist, werden die in das Datenfeld übertragenen Daten entsprechend der angegebenen Maskenzeichenfolge druckaufbereitet.
Die Maskenzeichenfolge ist auf bestimmte Kombinationen der Zeichen:B, / (Schrägstrich), P, V, Z, 0 (Null), 9, , (Komma), . (Dezimalpunkt),
*, +,-, CR, DB und $ (Währungszeichen) beschränkt. Die zulässigen Kombinationen werden von Druckaufbereitungsregeln und der Präzedenzreihenfolge der Zeichen bestimmt (siehe Abschnitt „PICTURE-Klausel"). Die maximale Zahl von Ziffern in einer Maskenzeichenfolge für ein numerisch druckaufbereitetes Datenfeld ist 31.Daten werden mit einem Zeichen pro Byte gespeichert. Der Inhalt einer Zeichenstelle, die eine Ziffer darstellt, muss eine der Ziffern 0 bis 9 sein.
Das Datenformat eines numerisch druckaufbereiteten Datenfeldes ist immer DISPLAY.
Numerische Datenfelder
Es gibt zwei Arten der Darstellung von numerischen Datenfeldern, Festpunktdatenfelder und Gleitpunktdatenfelder. Für die interne Darstellung von numerischen Datenfeldern siehe Tabelle 17 im Abschnitt "COMPUTATIONAL-3-Angabe oder PACKED-DECIMAL-Angabe".
Festpunktdatenfelder
Ein Festpunktdatenfeld ist ein numerisches Datenfeld, in dem der Rechendezimalpunkt in jedem Wert immer als vorhanden angenommen oder an einer festen Stelle relativ zum Beginn oder Ende des Speicherbereichs festgehalten wird, der für das Datenfeld belegt ist. Der Inhalt eines Festpunktdatenfeldes muss sich, falls die SIGN-Klausel nicht angegeben ist, aus den Ziffern 0 bis 9 zusammensetzen. Ist die SIGN-Klausel angegeben, darf der Inhalt zusätzlich zu den obigen Ziffern noch +,
-oder andere Darstellungen des Vorzeichens enthalten. Falls die Maskenzeichenfolge für ein Festpunktdatenfeld ein S enthält, wird der Inhalt des Datenfeldes als positiver oder negativer Wert behandelt, abhängig vom Rechenvorzeichen. Falls die Maskenzeichenfolge kein S enthält, wird der Inhalt des Datenfeldes als absoluter Wert behandelt.Maskenzeichenfolgen für Festpunktdatenfelder dürfen nur die symbolischen Zeichen 9, P, S und V enthalten.
COBOL kennt drei Arten von Festpunktzahlen:
extern dezimal
(USAGE IS DISPLAY)
binär
(USAGE IS COMPUTATIONAL oder COMPUTATIONAL-5 oder
USAGE IS BINARY)intern dezimal
(USAGE IS COMPUTATIONAL-3 oder USAGE IS PACKED-DECIMAL)
Die Beschreibung der Unterschiede ist unter Abschnitt „USAGE-Klausel" aufgeführt.
Gleitpunktdatenfelder
Ein Gleitpunktdatenfeld ist ein numerisches Datenfeld, dessen Dezimalpunkt verschiebbar ist, d.h. der Dezimalpunkt kann an verschiedenen Stellen stehen und wird durch die Angabe eines Exponenten der Basis (10) festgelegt. Die Basis, damit exponentiert, dient als Koeffizient einer Festpunktzahl (Mantisse); damit ist die Gleitpunktzahl dargestellt.
Gleitpunktdatenfelder werden nur für Daten benutzt, deren potenzieller Wertebereich zur Festpunktdarstellung zu groß ist.
Es gibt zwei Arten von Gleitpunktdatenfeldern: externe Gleitpunktdatenfelder und interne Gleitpunktdatenfelder.
Externe Gleitpunktdatenfelder
Die Maskenzeichenfolge für ein externes Gleitpunktdatenfeld kann die Zeichen. (Dezimalpunkt), V, E, + und
-enthalten. Jedes Zeichen, außer V, belegt ein Byte des Speichers und ist in jeder Druckausgabe enthalten (siehe „PICTURE-Klausel“, und „USAGE-Klausel“, für weitere Details).Das Datenformat eines externen Gleitpunktdatenfeldes ist immer DISPLAY.
Interne Gleitpunktdatenfelde
Es gibt zwei Arten von internen Gleitpunktdatenfeldern:
einfach genaue Datenfelder (USAGE IS COMPUTATIONAL-1) mit einer Länge von vier Bytes und
doppelt genaue Datenfelder (USAGE IS COMPUTATIONAL-2) mit einer Länge von acht Bytes.
Beide umfassen denselben Wertebereich. Das einfach genaue Datenfeld erlaubt sieben Dezimalziffern Genauigkeit. Das doppelt genaue Datenfeld erlaubt sechzehn Dezimalziffern Genauigkeit.
Eine PICTURE-Klausel ist für interne Gleitpunktzahlen nicht anzugeben; die Länge eines solchen Datenfeldes ist durch seine USAGE-Klausel bestimmt.
Objekt und Objektreferenz
Eine Objektreferenz ist ein implizit oder explizit definiertes Datenelement. Der Inhalt der Objektreferenz verweist eindeutig auf ein Objekt und seine zugehörigen Informationen.
Programmzeiger
Ein Programmzeiger ist ein Datenelement, in dem die Adresse eines Programms gespeichert werden kann.
4. Algebraische Vorzeichen
Es gibt zwei Kategorien algebraischer Vorzeichen:
Rechenvorzeichen, die mit vorzeichenbehafteten numerischen Datenfeldern und vorzeichenbehafteten numerischen Literalen zusammenhängen, um ihre algebraischen Merkmale aufzuzeigen,
Druckaufbereitungsvorzeichen, die z.B. in druckaufbereiteten Listen zum Bezeichnen des Vorzeichens des Datenfeldes auftreten.
Druckaufbereitungsvorzeichen werden in ein Datenfeld durch Verwendung des Vorzeichen-Steuerzeichens der jeweiligen Maskenzeichenfolge (siehe Abschnitt „PICTURE-Klausel") eingefügt.
5. Ausrichtung von Daten
Die Ausrichtung von Daten innerhalb von Datenelementen hängt von der Kategorie des Empfangsfeldes ab.
Numerische Datenfelder
Falls das Empfangsfeld als numerisch beschrieben ist, wird das Sendedatum am Dezimalpunkt ausgerichtet in die Ziffernstellen des Empfangsfeldes übertragen. Ist das Sendedatum kürzer als das Empfangsfeld, werden die nicht verwendeten Ziffernstellen mit Nullen aufgefüllt. Ist das Sendedatum länger als das Empfangsfeld, wird es von links bzw. von rechts abgeschnitten.
Wenn ein Rechendezimalpunkt nicht ausdrücklich angegeben ist, wird das Empfangsfeld so behandelt, als hätte es einen Rechendezimalpunkt unmittelbar nach der am weitesten rechts stehenden Ziffer. Ausrichtung und Übertragung erfolgen wie oben beschrieben.Numerisch druckaufbereitete Datenfelder
Falls das Empfangsfeld ein numerisch druckaufbereitetes Datenfeld ist, erfolgt die Ausrichtung und Übertragung des Sendedatums wie bei numerischen Empfangsfeldern, wobei durch spezielle Druckaufbereitungsangaben führende Nullen durch andere Zeichen ersetzt werden können.
Alphanumerische, alphanumerisch druckaufbereitete, alphabetische und nationale Datenfelder
Falls das Empfangsfeld alphanumerisch (anders als ein numerisch druckaufbereitetes Datenfeld), alphanumerisch druckaufbereitet, alphabetisch oder national ist, wird das Sendedatum von links nach rechts in die Zeichenstellen des Empfangsfeldes übertragen. Ist das Sendedatum kürzer als das Empfangsfeld, werden die nicht verwendeten Zeichenstellen mit Leerzeichen entsprechend der Klasse des Empfangsfeldes aufgefüllt. Ist das Sendedatum länger als das Empfangsfeld, werden die überschüssigen Zeichen des Sendedatums abgeschnitten.Falls die JUSTIFIED-Klausel für das Empfangsfeld angegeben ist, siehe Beschreibung der JUSTIFIED-Klausel ( Abschnitt „JUSTIFIED-Klausel").
Datenfeldausrichtung für schnelleren Ablauf des Programms
Bestimmte Daten (in arithmetischen Operationen oder in Subskribierungen) können schneller verarbeitet werden, wenn die Daten an „natürlichen“ Grenzen (Halbwort, Wort, Doppelwort) ausgerichtet sind.
Es sind zusätzliche Maschinenbefehle für den Zugriff und das Abspeichern von Daten notwendig, falls Teile von zwei oder mehr Datenfeldern zwischen zwei benachbarten natürlichen Grenzen vorkommen oder falls bestimmte natürliche Grenzen ein einzelnes Datenfeld aufteilen.
Datenfelder, die an diesen „natürlichen“ Grenzen so ausgerichtet sind, dass sie zusätzliche Maschinenbefehle vermeiden, sind als ausgerichtet („synchronized“) definiert. Immer ausgerichtet werden Datenfelder der Klassen index, objekt und zeiger (siehe Tabelle 16 „Ausrichtung von Datenfeldern" im Abschnitt "SYNCHRONIZED-Klausel").Für diese Form des Ausrichtens hat der Benutzer zwei Möglichkeiten:
Angabe der SYNCHRONIZED-Klausel (siehe Abschnitt „SYNCHRONIZED-Klausel"),
geeignetes Organisieren der Daten unter Berücksichtigung der entsprechenden natürlichen Grenzen.
Näheres hierzu siehe nächster Abschnitt.