The new, third format of the READ statement just for XML files is used for reading one or more nodes from the XML document tree. Reading an XML document differs from how a file was read to date in several respects:
The fixed, known data set 'record' which an old READ statement transfers has no equivalent in XML documents. Rather, the new READ statement transfers data on a set of nodes in the tree (element and/or attribute nodes) which may vary from statement to statement.
The fixed, implicit range 'next record' in the case of a old, sequential READ statement or 'whole file' in the case of a new, optional READ statement has no equivalent in XML documents. Rather, the range of the new READ statement – one or more subtrees of the document – must be specified in the statement.
The 'sequential' and 'random' access types which are possible with an old READ statement have no equivalents in XML documents. Rather, in the new READ statement the access type is defined statically for each node in the 01 structures of the FD.
The one key (primary or alternate) for random access in an old READ statement has no equivalent in XML documents. Rather, the 01 structures define the keys, and the individual new READ statement specifies which subset of these keys is to be used.
The new READ statement handles element nodes and attribute nodes differently when reading. This is not the case with the old READ statement.
The differences described above are reflected in the extended 01 data structures in the FD and the syntax and semantics of the new READ statement which differ from the old READ statement:
As a rule only some of the data described in a 01 data structure is supplied with data – there is no INTO phrase (see also 1.). Data items can exist in the record description entry which is never modified by READ statements, e.g. the data item specified in IDENTIFIED BY.
The range (see also 2.) is specified in the form of a data item in the new READ statement. A node in the tree must be assigned to this data item. This node determines the range:
If assignment took place using an OPEN or START statement, it covers the subtree defined by this node and the subtrees defined by its younger siblings.
If assignment took place using a READ statement, it covers only the subtrees defined by the younger siblings.
The IDENTIFIED clauses in the record description entries of the FD define the access type (see also 3.):
BY: random access
USING: sequential access without the option of reading backward; there is no PREVIOUS phrase.
It is not possible to switch from random to sequential reading (see also 3.) – there is no NEXT phrase. Further element nodes with the same name (i.e. the repetitions mentioned above) can also be read randomly because a node which has just been read no longer belongs to the range of a subsequent READ statement with an unchanged key.
The data item which must be specified in the new READ statement also defines the subset of the keys to be used for random access (see also 4.). There is no KEY phrase. The following applies for the data item specified and all the data items which are subordinate to it:
The specifications made with IDENTIFIED BY describe the keys for random access.
The specifications made with IDENTIFIED USING describe the data items in which the name of the element or attribute node read sequentially is made available.
The (context-sensitive) keywords ATTRIBUTE and ELEMENT specify the type of node to be processed by the READ statement (see also 5.).
A new READ statement looks like this:
READ xml-file ELEMENT data-name-1
or
READ xml-file ATTRIBUTE data-name-1
where data-name-1 is the name of the data item with an IDENTIFIED clause, in other words with the description of a node in the COBOL structure (not to be confused with the data item which contains the name of the node and which may have been specified in the IDENTIFIED clause). The ELEMENT or ATTRIBUTE phrase specified there must match the phrase in the READ statement.
The specified data item data-name-1 is decisive for the new READ statement. Consequently 'reading the file' is no longer spoken of in this context, but ’reading via (data item) dataname-1.’
A prerequisite for successful execution of the READ statement is that the assignment of a node from the tree to the specified data-name-1 already exists. When the READ statement is executed,
the FD node is assigned to (a few) data items in a 01 structure,
for individual nodes data is transferred from the tree to the COBOL data structure.
Assignment
The assignment procedure begins in the first step on the COBOL side with the data item which was specified in the READ statement.
Further assignments are then implemented, as described under "Assignment procedure" in section "Statements for XML processing" . |
- Data items in the structure which are above the specified data item, next to it on the same level or in other 01 structures of the FD are not taken into consideration,and their assignment in the EPV remains unchanged.
- Existing positions for data items which are subordinate to the data item specified in the READ statement are irrelevant for assignment.
- It actually seems superfluous to include data item data-name-1 (for which an assigned node was already required as a prerequisite) in the assignment procedure again. However, this assignment need not necessarily still apply if, for example, in the case of random access the value of a key has changed in the meantime.
- As attribute names must be unique, the order of the attribute nodes is irrelevant. There can at most be one suitable name. In this case all attribute nodes are therefore always checked for a possible assignment.
Data transfer
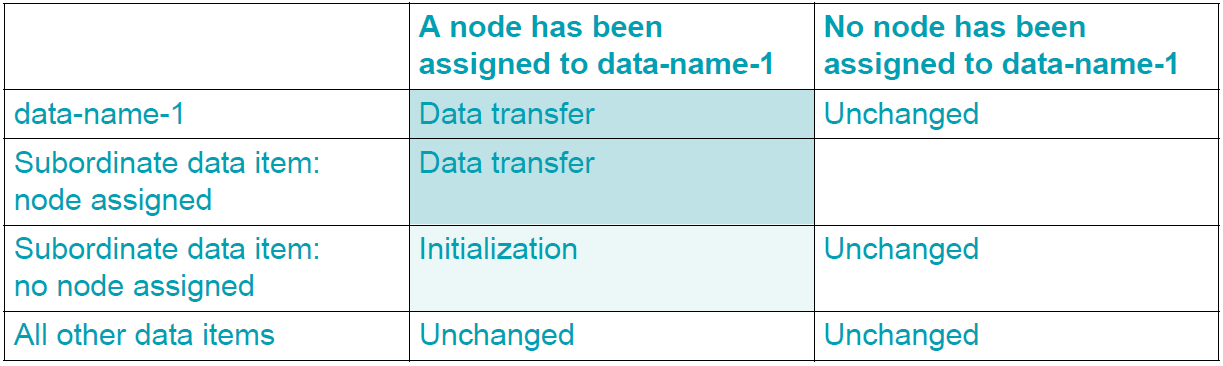
The data-name-1 specified in the READ statement splits the data items defined in the FD into three sets: data-name-1 itself, the data items subordinate to it, and all other data items from the FD.
Depending on whether a node is successfully assigned to data-name-1, the affiliation to one of the three sets and the assignment of nodes to the subordinate data items, data items remain unchanged, are initialized, or are supplied with data from the tree. This is illustrated in the table below:
The sending items in the XML document tree with USAGE NATIONAL (i.e. UTF-16) must be implied for data transfer.
Data transfer or initialization takes place in accordance with the COBOL rules (for this purpose conversion according to FUNCTION DISPLAY-OF takes place when transferring values from the tree to alphanumeric receiving items, and according to FUNCTION NUMVAL-C when transfer is to numeric receiving items, without a second parameter). For a node described in the COBOL structure (i.e. a data item with an IDENTIFIED clause), data transfer or initialization here concerns any data items for accommodating the name, the value and the display which may be connected to the node:
Data transfer | Initialization | |
Data item from USING phrase in IDENTIFIED clause | Name of the node from the tree | Blank |
Data item for the value | Value of the node from the tree | Initialized by means of INITIALIZE...TO DEFAULT |
Data item from COUNT clause | 1 | 0 |
Example 12-42 Sequential reading
XML document | Pos | COBOL data structure | OPEN | READ | READ | READ |
<doc>000 | 1 | FD xml-fil | | | | |
FILE STATUS | 00 | 00 | 08 | 10 |
Comments:
Information on the presentation of this example is provided in section "Statements for XML processing".
Successful assignment of a node (node 2) using the OPEN DOCUMENT statement is sufficient for reading via y. It is not necessary that superordinate data items (x) should already have been read in the 01 structure.
Reading via y takes place sequentially as IDENTIFIED USING is specified.
The position assigned to y before the first READ statement was set by an OPEN DOCUMENT statement. Consequently the subtrees with roots nodes 2 and 3 (in this order) can be taken into consideration as the range. Node 2 is assigned, and the name and value of the node read are transferred.
Only one single data item which is not referenced in the IDENTIFIED clause may be subordinate to a data item with an IDENTIFIED clause: the value of the assigned node is transferred to this field (y value).
If the value of a node is of no significance for the program, the data item for it can also be completely omitted, as with data item x.
After the first READ statement, y is still assigned to node 2. However, the position indicates that it was created by READ. Only younger siblings, i.e. node 3, can be taken into consideration in the following READ statement.
In the second READ statement the assigned subtree contains a node (c) which is not described in the corresponding COBOL structure y. I-O status 08 displays this.
In the third READ statement the assigned node 3 has no younger siblings, and consequently the at end condition is created. The data items for name and value remain unchanged.
Example 12-43 Random reading and repetitions
XML document | Pos | COBOL data structure | OPEN | READ | READ | READ |
<doc>000 | 1 | FD xml-fil | | |
|
|
FILE STATUS | 00 | 00 | 00 | 10 |
Comments:
Information on the presentation of this example is provided in section "Statements for XML processing".
Reading via y takes place randomly as IDENTIFIED BY is specified. The current value of the key is 'a'.
The position assigned to y in the first READ statement was set by an OPEN DOCUMENT statement. Consequently the subtrees with roots nodes 3, 4 and 5 are taken into consideration as the range. Node 3 is the first of these which can be assigned.
After the first READ statement, node3 is still assigned to y. However, the position now indicates that it was created by READ.
The range of the second READ statement includes the subtrees with roots nodes4 and 5. Of these, node 4 can be assigned. As node 3 is no longer part of the range, this READ statement reads the repetition, i.e. the second example of the node with the name 'a'.
In the third READ statement the assigned node 4 does have a younger sibling (node 5), but no assignment is possible because the name does not match.
In the event of random reading, an at end condition may also occur.
Example 12-44 Random reading with changing key value
XML document | Pos | COBOL data structure | OPEN | READ | READ | |
<doc>000 | 1 | FD xml-fil | | | | |
Comments:
Information on the presentation of this example is provided in section "Statements for XML processing".
Up to and including the first READ statement this example is no different to the previous one.
As in the previous example, the range of the second READ statement includes the subtrees with the roots nodes 4 and 5. Changing the value of the y-name key to 'c' now causes node 5 to be assigned.
As the OPEN DOCUMENT statement was executed with the key value 'a', node 2 can never again be reached by reading via y despite the subsequently modified and actually suitable key value 'c'. The open function assigned node 3 to y. Consequently only this node and its younger siblings - but not the older sibling node 2 - come into consideration as the range for all further READ statements.
Example 12-45 Effect of changing key values
XML document | Pos | COBOL data structure | OPEN | READ | READ | |
<doc>111 | 1 | FD xml-fil | | |
| |
Comments:
Information on the presentation of this example is provided in section "Statements for XML processing".
Modifications to key values (y-name and z-name) after successful assignment following the OPEN DOCUMENT statement do not always affect subsequent assignments.
The two MOVE statements after OPEN DOCUMENT suggest that the first READ statement should access the subtree with root node 5 (name = 'b') randomly and in this access node 7 (name = 'd'). However, reading via data item z is not suitable for this purpose.
Values of keys which in the COBOL structure are superordinate (y with y-name) to the key used while reading (z with z-name) are not taken into consideration during assignment. Changes to such key values have no effect. In the example access continues to take place in the assigned subtree with root 2, and in this to node 4.
In addition to changing the key values, reading must also take place via a data item which is not subordinate to any of the modified keys, such as data item y in the second READ statement.
Example 12-46 Transferred data
XML document | Node | COBOL data structure | OPEN | READ xml-fil ELEMENT x |
<doc>000 | 1 | FD xml-fil | | |
Comments:
Information on the presentation of this example is provided in section "Statements for XML processing".
In the case of random reading, the order of the data items in the COBOL structure – first y for nodes with the name 'b', then z for nodes with the name 'a' – and that of the assigned nodes in the tree – first that with the name 'a', then that with the name 'b' – is irrelevant.
Non-numeric values from the tree which are too short are filled with blanks (x-value), Values which are too long are truncated (y-value).
Numeric values are transferred on a decimal-point-oriented basis (z-value), possibly also converted to another USAGE.
The COUNT elementary items indicate whether nodes could be assigned to a data item (z-count) or not (u-count). Only the READ statement sets this display.
The keywords are case-sensitive. Node 4 with the name 'c' is consequently not assigned to data item u with the key value 'C'.
Data items which are subordinate to the data item via which reading took place (x) and to which no node is assigned (u) have invalid items in the EPV and are initialized.
Example 12-47 Elements and attributes
XML document | Pos | COBOL data structure | OPEN | READ xml-fil | READ xml-fil | READ xml-fil | READ xml-fil |
<doc | 1 | FD xml-fil | | |
|
|
|
| FILE STATUS | 00 | 08 | 00 | 00 | 10 |
Comments:
Information on the presentation of this example is provided in section "Statements for XML processing".
The OPEN DOCUMENT statement assigns both element nodes and attribute nodes simultaneously.
In the case of predefined keys, node 3 is assigned to attribute x-att1 (key='d2'). No node can be assigned to attribute x-att2 (key='d3'). If no keys are defined, the first attribute node (node 5) is assigned to attribute y-att.
The COUNT clause can also be used for attributes (x-att2).
Attribute d2, which is not described in the COBOL structure, results in I-O status 08 when reading takes place via x.
The rule with the range also applies for sequential reading of attributes, even if the subtrees here only consist of one node. The range of the second READ statement includes nodes 6 and 7. As every name fits in the case of sequential access, node 6 is therefore assigned.
It is not necessary to read sequentially to the end via a data item, e.g. also 'a3' via y-att. Another elementary item may be switched to beforehand (y).
The third READ statement (via y) assigns node 8 to y and the first attribute 'a1' of this node (node 9) to the subordinate attribute (y-att).
When an end is reached in sequential reading, this is noted in the EPV (for data item y). In this case the EPV entries for all subordinate data items are set to invalid (y-att). However, the values of the data items remain unchanged (y-name, y-value, y-att-name, y-att-value).
BY (x-att1) and USING (y) may be specified for data items with the same immediate superordinate group item (x) because they describe different types of nodes (attribute and element respectively).
Example 12-48 Random reading of attributes
XML document | Pos | COBOL data structure | OPEN | READ | READ | READ | |
<doc | 1 | FD xml-fil |
|
|
| |
|
Comments:
Information on the presentation of this example is provided in section "Statements for XML processing".
The first READ statement assigns the attribute node 4 with the predefined key 'a2' to y-att.
The second READ statement for random reading of an attribute therefore examines – because of the unchanged key – nodes 3, 4 and 5 for a possible assignment, i.e. the node already assigned and all its siblings: it assigns node 4 once again.
Since all nodes are examined when attributes are read randomly (in contrast to the ELEMENT phrase, cf. the example "Random reading and repetitions" ), the at end condition can never occur in the case of an unchanged key (which also exists in the tree).
Since all sibling nodes are examined when attribute nodes are read randomly, changing the key value (to 'a1') with the third READ statement also permits older siblings (node 3) of the node assigned to data item y-att (node 4) to be read.
Example 12-49 Multiple reading of the same node
XML document | Pos | COBOL data structure | OPEN | READ | READ | READ |
<doc>111 | 1 | FD xml-fil |
|
|
|
|
Comments:
Information on the presentation of this example is provided in section "Statements for XML processing".
Data on node 3 is supplied through reading via z. The second READ statement sets the position of z to node 4.
Only the position which y assigns itself (node 2) is relevant for subsequent reading via the superordinate data item. The positions of subordinate data items (z) are irrelevant.
The third READ statement then assigns node 3 to z again and also supplies its data (not the data of node 5).
Restricted data transfer using ONLY
As an option, READ permits ONLY to be specified before the keyword ELEMENT. In this case data is only transferred in conjunction with the data item specified in the READ statement, if necessary including any existing attributes. No data transfer takes place for any other subordinate data items. However, node assignment also takes place for the subordinate data items. As no data has yet been transferred for the subordinate data items, in the case of subsequent read accesses its EPV entry must be interpreted as if it had been created by an OPEN DOCUMENT statement.
ONLY is forbidden for reading attributes and also makes no sense, because attribute nodes have no children.
Example 12-50 Restricted data transfer using ONLY
XML document | Pos | COBOL data structure | OPEN | READ | READ | READ |
|
<doc>1 | 1 | FD xml-fil | |
|
|
|
|
Comments:
Information on the presentation of this example is provided in section "Statements for XML processing".
The first READ statement reads node 2 with its attribute node 3, as well as the subordinate node 4. The following READ statement via the subordinate data item z reads the next node 5 sequentially.
By way of comparison, this is how reading takes place in a subtree which has a similar structure and root 6, but has an ONLY phrase, i.e. with no transfer of the subordinate elements: the name and value of the element ('a' and '6') are transferred for data item y from the READ statement. Data transfer ('B') also takes place for the data items which are subordinate to y and describe attribute nodes (y-att).
Nodes (node 8) are assigned for the data items which are subordinate to y and describe element nodes (here only z), but no data is transferred. Data contained in the COBOL structure remains unchanged. The assignment in the EPV records that it was not created by READ.
The subsequent fourth READ statement via the subordinate data item (z) now first transfers the name and value of the assigned node 8, not the name and value of the following node like the second READ statement.
Summary
In summary, the following must be observed in the case of the READ statement:
Random read access to elements only ever permits access to children and younger siblings, but never to parents or older siblings.
Random read access without an intermediate OPEN or START statement or modification of the key supplies the repetitions in the case of an element node and the at end condition after the last copy. In the case of attribute nodes, the same (sole) copy is supplied repeatedly.
Data in mixed content resulting from inserted, subordinate elements is combined to form one piece.
A READ statement without an ONLY phrase supplies the value 08 for the I-O status if the subtree used for assignment contains at least one node below the root which can never be assigned to a data item in the COBOL structure.
The fundamental option of being able to assign the node to a data item is involved here. This has nothing to do with whether this assignment has been implemented in the current READ statement and data has been transferred. In particular this means: repetitions of element names in the tree of which a copy could be assigned do not result in value 08 for the I-O status.
In the case of a READ statement containing the ONLY phrase, I-O status 08 can only exist for non-assignable attributes of the element which was read, but not for other nodes of the subtree examined.
Current positions or assigned nodes for data items which are subordinate in the COBOL structure to the data item specified in the READ statement are irrelevant.
The data item specified in the READ statement determines simultaneously where the search/reading is to take place and what is to be searched for/read.
A READ statement is generally a mixture of sequential and random access, all element children and attribute children of a node being accessed in the same way, irrespective of how the node itself is accessed.
In the EPV a READ statement only changes the position of the data item via which reading takes place and of the data items which are subordinate to this data item. The positions of all other data items remain unchanged.