Allen Client/Server-Architekturen liegt eine Gliederung in einzelne Software-Komponenten, auch „Schichten“ oder „Tiers“ genannt, zu Grunde (der Begriff „Tier“, übersetzt: „Stufe“, kommt aus dem Englischen, setzt sich aber auch im deutschen Sprachraum immer mehr durch). Man spricht von 1-Tier-, 2-Tier-, 3-Tier und auch von Multi-Tier-Modellen. Dabei wird oft nicht klar unterschieden, ob man die Aufgliederung auf der physischen oder auf der logischen Ebene betrachtet:
Logische Software-Tiers liegen vor, wenn die Software in modulare Komponenten mit klaren Schnittstellen gegliedert ist - unabhängig davon, wie diese Komponenten im Netz verteilt sind.
Physische Software-Tiers liegen dann vor, wenn die (logischen) Softwarekomponenten im Netz auf verschiedene Rechner verteilt sind.
In Bild 12 sind die fünf Client/Server-Basismodelle mit jeweils zwei physischen Software-Tiers dargestellt:
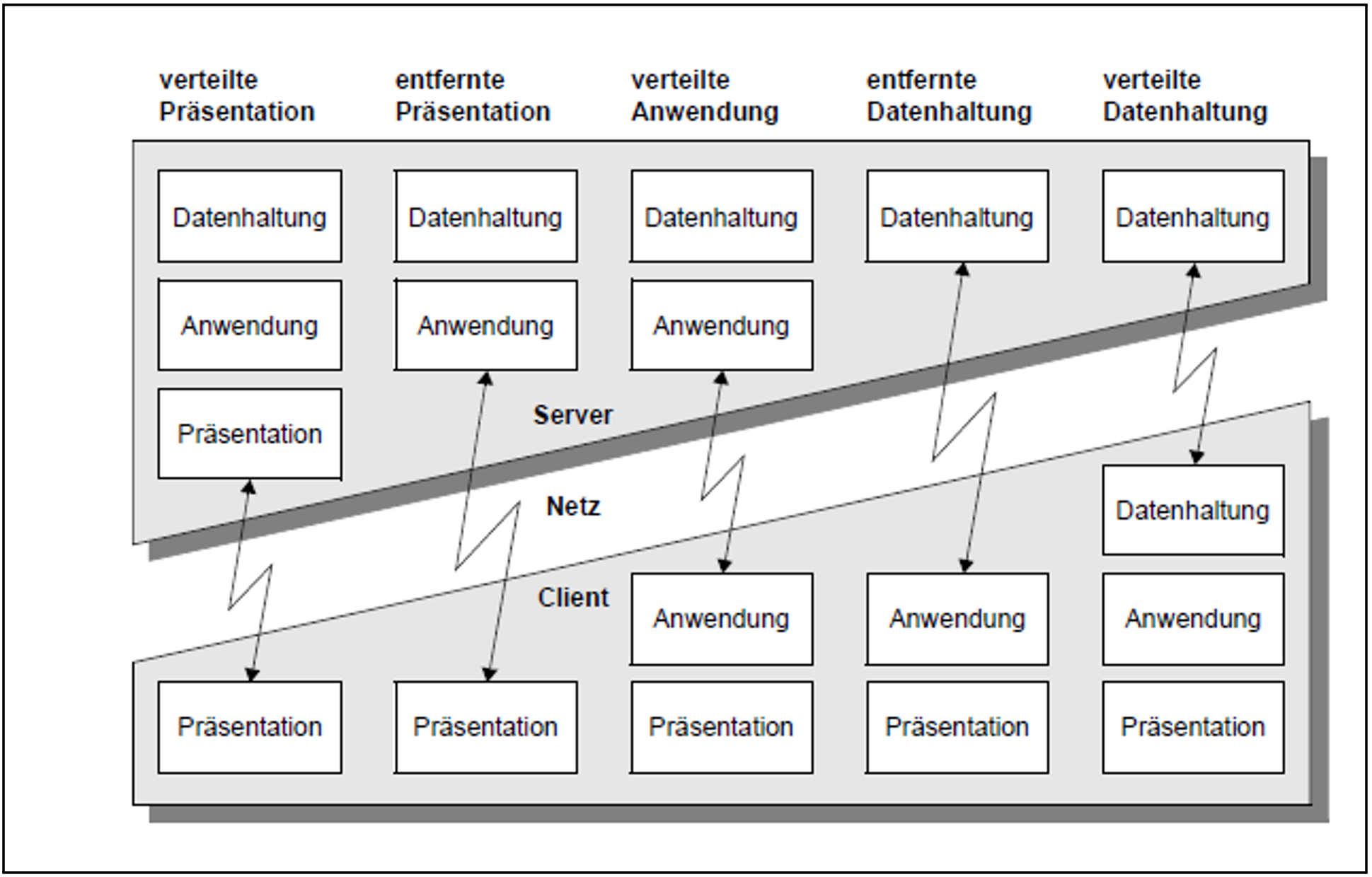
Bild 12: Basismodelle für Client/Server-Architekturen
openUTM unterstützt nicht nur die in Bild 12 dargestellten Grundschemata, sondern vielfältige Abwandlungen und Kombinationen. Mit openUTM sind komplexe Multi-Tier-Szenarien möglich - sowohl auf der Ebene physischer als auch auf der Ebene logischer Tiers.
Wie Bild 13 zeigt, erlaubt openUTM nicht nur die Verteilung von Daten oder Anwendungslogik, sondern auch beliebige Kombinationen. Dadurch können Daten an den Stellen abgelegt werden, an denen sie auch verarbeitet werden. Die Netzbelastung wird minimiert, da nicht mehr umfangreiche Datenmengen, sondern nur noch Aufträge und Ergebnisse über das Netz gehen. openUTM gewährleistet dabei, dass die Daten zu jedem Zeitpunkt global konsistent sind.
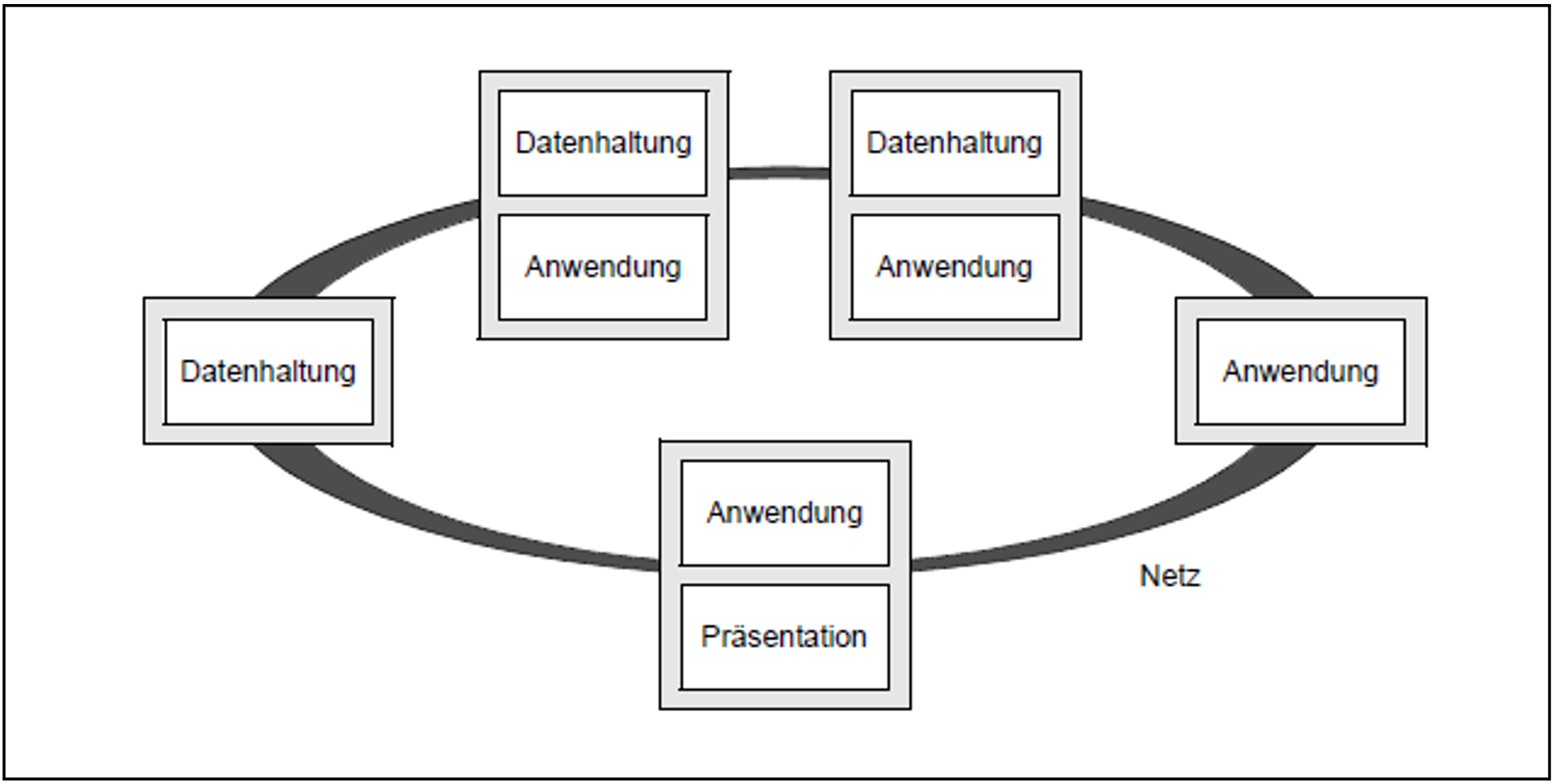
Bild 13: Multi-Tier-Architektur
Nachteile herkömmlicher 2-Tier-Architekturen / Vorteile von Multi-Tier-Verteilung
Viele herkömmliche Client-Server-Anwendungen basieren auf einer klassischen 2-Tier-Architektur: Der Server ist für die Datenhaltung zuständig, während der Client möglichst alle anderen Aufgaben übernimmt. Dieses Modell hat jedoch eine Reihe von Nachteilen:
Da Clients und Server meist auf SQL-Ebene kommunizieren, gehen dabei oft unnötig große Datenmengen über das Netz (Round Trips). Gerade bei einer großen Benutzerzahl und bei Kommunikation über langsame WAN-Strecken werden die Antwortzeiten inakzeptabel.
Auch ist bei solchen Architekturen die Systempflege zeitaufwendig und teuer, da die Anwendungslogik auf den Client-Rechnern implementiert ist. Dies führt gerade bei größeren Anwendungen in heterogenen Umgebungen zu nicht unerheblichen Redundanzen und Wartungsproblemen, da jede Änderung der Anwendungslogik eine Nachpflege eventuell mehrerer Quellprogramm-Basen nach sich zieht. Weil das Datenmodell - zumindest teilweise - auf den Clients sichtbar ist, führen Änderungen bei der Datenhaltung unweigerlich zu Anpassungen der Client-Software.
Erweiterungen der Anwendungslogik führen zu einem Wachstum an Code und Ressourcenbedarf der Clients, es droht das Fat Client Syndrom: Die Clients müssen aufgerüstet werden, eventuell ist sogar der Umstieg auf eine leistungsfähigere Plattform notwendig.
Um die geschilderten Probleme zu vermeiden bieten viele Datenbanksysteme die Möglichkeit, durch Stored Procedures oder Trigger-Funktionen zumindest Teile der Anwendungslogik auf den Server zu verlagern. Dabei werden aber oft proprietäre Script-Sprachen verwendet, die zur Laufzeit interpretiert werden müssen. Dies führt zu Performance-Einbußen. Zudem gibt es keine Möglichkeit, verschiedene Datenbanksysteme innerhalb einer Transaktion zu koordinieren.
Multi-Tier-Architekturen auf Basis von openUTM ermöglichen es, diese Einschränkungen und Engpässe zu umgehen. Die logischen Schichten: „Präsentation“, „Anwendung“ und „Datenhaltung“ sind auch physisch klar abgegrenzt und lassen sich beliebig verteilen. Die Netzbelastung wird minimiert, die System-Ressourcen werden geschont, heterogene Datenbanksysteme und Plattformen lassen sich koordinieren. Die Kosten für Systempflege bleiben gering. Bei Erweiterungen der Anwendung entsteht zusätzlicher Ressourcenbedarf nur an einer oder wenigen zentralen Stellen.