Das neue, dritte Format der READ-Anweisung nur für XML-Dateien dient dem Lesen eines oder mehrerer Knoten aus dem XML-Dokument-Baum. Das Lesen eines XML-Dokuments unterscheidet sich vom bisherigen Lesen einer Datei in mehrfacher Hinsicht:
Die feste, bekannte Datenmenge 'Satz', die eine bisherige READ-Anweisung überträgt, findet keine Entsprechung bei XML-Dokumenten. Vielmehr überträgt die neue READ-Anweisung Daten zu einer ggf. von Anweisung zu Anweisung variierenden Menge von Knoten des Baums (Element- und/oder Attribut-Knoten).
Der feste, implizite Wirkungsbereich 'nächster Satz' bei einer bisherigen, sequenziellen bzw. 'ganze Datei' bei einer bisherigen, wahlfreien READ-Anweisung findet keine Entsprechung bei XML-Dokumenten. Vielmehr muss der Wirkungsbereich der neuen READ-Anweisung – ein oder mehrere Teilbäume des Dokuments – explizit in der Anweisung angegeben werden.
Die bei einer bisherigen READ-Anweisung möglichen Zugriffsarten 'sequenziell' bzw. 'wahlfrei' finden keine Entsprechung bei XML-Dokumenten. Vielmehr ist bei der neuen READ-Anweisung die Zugriffsart für jeden Knoten statisch in den 01-Strukturen der FD festgelegt.
Der eine Schlüssel (primary oder alternate) für den wahlfreien Zugriff bei einer bisherigen READ-Anweisung findet keine Entsprechung bei XML-Dokumenten. Vielmehr definieren die 01-Strukturen die Schlüssel, und die einzelne neue READ-Anweisung gibt an, welche Teilmenge dieser Schlüssel jeweils zu verwenden ist.
Die neue READ-Anweisung behandelt Element-Knoten bzw. Attribut-Knoten beim Lesen unterschiedlich. Entsprechendes findet man bei der bisherigen READ-Anweisung nicht.
Diese aufgeführten Unterschiede spiegeln sich in den erweiterten 01-Datenstrukturen in der FD und der von der bisherigen READ-Anweisung abweichenden Syntax und Semantik der neuen READ-Anweisung wieder:
Es wird in der Regel nur ein Teil der in einer 01-Datenstruktur beschriebenen Daten versorgt – es gibt keine INTO-Angabe (siehe auch 1.). In der Satzbeschreibung kann es Datenfelder geben, die durch READ-Anweisungen nie geändert werden, z.B. das in IDENTIFIED BY angegebene Datenfeld.
Der Wirkungsbereich (siehe auch 2.) wird in Form eines Datenfeldes bei der neuen READ-Anweisung angegeben. Diesem Datenfeld muss ein Knoten des Baums zugeordnet sein. Dieser Knoten bestimmt den Wirkungsbereich:
Wenn die Zuordnung durch eine OPEN- oder START-Anweisung erfolgte, umfasst er den durch diesen Knoten festgelegten Teilbaum und die durch seine jüngeren Geschwister festgelegten Teilbäume.
Wenn die Zuordnung durch eine READ-Anweisung erfolgte, umfasst er nur die durch die jüngeren Geschwister festgelegten Teilbäume
Die IDENTIFIED-Klauseln in den Satzbeschreibungen der FD legen die Zugriffsart (siehe auch 3.) fest:
BY: wahlfreier Zugriff
USING: sequenzieller Zugriff, ohne die Möglichkeit, rückwärts zu lesen; es gibt keine PREVIOUS-Angabe.
Der Wechsel von wahlfreiem zu sequenziellem Lesen (siehe auch 3.) ist nicht möglich – es gibt keine NEXT-Angabe. Das Lesen von weiteren Element-Knoten mit gleichem Namen (d.h. die oben erwähnten Wiederholungen) ist auch wahlfrei möglich, da ein ge-rade gelesener Knoten nicht mehr zum Wirkungsbereich einer nachfolgenden READ-Anweisung mit unverändertem Schlüssel gehört.
Das bei der neuen READ-Anweisung anzugebende Datenfeld legt gleichzeitig auch die Teilmenge der für den wahlfreien Zugriff zu verwendenden Schlüssel fest (siehe auch 4.). Es gibt keine KEY-Angabe. Für das angegebene Datenfeld und alle ihm untergeordneten Datenfelder gilt:
Die mit IDENTIFIED BY gemachten Angaben beschreiben die Schlüssel für wahlfreien Zugriff.
Die mit IDENTIFIED USING gemachten Angaben beschreiben die Datenfelder, in denen der Name des sequenziell gelesenen Element- bzw. Attribut-Knoten zur Verfügung gestellt wird.
Die (kontextsensitiven) Schlüsselwörter ATTRIBUTE bzw. ELEMENT geben die Art des von der READ-Anweisung zu bearbeitenden Knotens an (siehe auch 5.).
Eine neue READ-Anweisung sieht kurz folgendermaßen aus:
READ xml-file ELEMENT datenname-1
oder
READ xml-file ATTRIBUTE datenname-1
Dabei ist datenname-1 der Name eines Datenfeldes mit IDENTIFIED-Klausel, also mit der Beschreibung eines Knotens in der COBOL-Struktur (nicht zu verwechseln mit dem in der IDENTIFIED-Klausel ggf. angegebenen Datenfeld, das den Namen des Knotens enthält). Die dort gemachte Angabe ELEMENT bzw. ATTRIBUT muss mit derjenigen in der READ-Anweisung übereinstimmen.
Das angegebene Datenfeld datenname-1 ist entscheidend für die neue READ-Anweisung. Daher ist in diesem Zusammenhang nicht mehr vom 'Lesen der Datei' die Rede, sondern vom ’Lesen über (Datenfeld) datenname-1’.
Voraussetzung für die erfolgreiche Ausführung der READ-Anweisung ist, dass bereits die Zuordnung eines Knotens aus dem Baum zu dem angegebenen datenname-1 existiert. Bei der Ausführung der READ-Anweisung werden dann
(einigen) Datenfeldern in einer 01-Struktur der FD Knoten zugeordnet,
zu einzelnen Knoten Daten aus dem Baum in die COBOL-Datenstruktur übertragen.
Zuordnung
Der Zuordnungsvorgang beginnt im ersten Schritt auf der COBOL-Seite mit dem Datenfeld, das in der READ-Anweisung angegeben wurde.
Anschließend werden weitere Zuordnungen durchgeführt, wie unter "Zuordnungsvorgang" beschrieben. |
Datenfelder in der Struktur über dem angegebenen Datenfeld, auf gleicher Stufe daneben oder in andern 01-Strukturen der FD werden nicht betrachtet, und ihre Zuordnung im EPV bleibt unverändert.
Bereits existierende Positionen für Datenfelder, die dem in der READ-Anweisung angegebenen Datenfeld untergeordnet sind, spielen für die Zuordnung keine Rolle.
Es scheint eigentlich überflüssig, das Datenfeld datenname-1, für das als Voraussetzung schon ein zugeordneter Knoten verlangt wurde, erneut in das Zuordnungsverfahren mit einzubeziehen. Diese Zuordnung muss jedoch aktuell gar nicht mehr zutreffen, wenn sich etwa bei wahlfreiem Zugriff inzwischen der Wert eines Schlüssels geändert hat.
Da Attributnamen eindeutig sein müssen, spielt die Reihenfolge der Attribut-Knoten keine Rolle. Es kann maximal einen passenden Namen geben. Daher werden in diesem Fall auch immer alle Attribut-Knoten auf mögliche Zuordnung überprüft.
Datenübertragung
Der in der READ-Anweisung angegebene datenname-1 teilt die in der FD definierten Datenfelder in drei Mengen: den datenname-1 selbst, die ihm untergeordneten Datenfelder und alle anderen Datenfelder aus der FD.
Abhängig von der erfolgreichen Zuordnung eines Knotens zu datenname-1, der Zugehörigkeit zu einer der drei Mengen und der Zuordnung von Knoten zu den untergeordneten Datenfeldern, bleiben Datenfelder unverändert, werden initialisiert oder mit Daten aus dem Baum versorgt. Dies verdeutlicht die nachfolgende Tabelle:
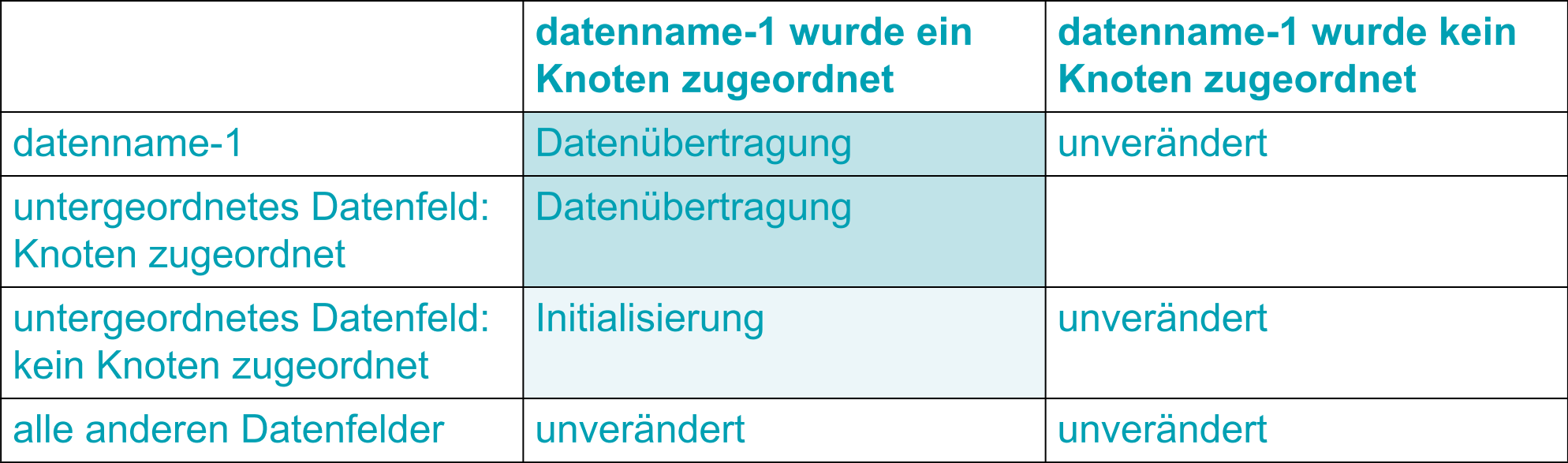
Für die Datenübertragung sind die Sendefelder im XML-Dokument-Baum mit USAGE NATIONAL (d.h. UTF-16) anzunehmen.
Die Datenübertragung bzw. Initialisierung erfolgt entsprechend den COBOL-Regeln (dazu findet bei Übertragung von Werten aus dem Baum zu alfanumerischen Empfangsfeldern eine Konvertierung entsprechend FUNCTION DISPLAY-OF statt, zu numerischen Empfangsfeldern entsprechend FUNCTION NUMVAL-C, ohne einen zweiten Parameter). Die Datenübertragung bzw. Initialisierung betrifft dabei für einen in der COBOL-Struktur beschriebenen Knoten (d.h. ein Datenfeld mit IDENTIFIED-Klausel) die damit ggf. verbundenen Datenfelder zur Aufnahme des Namens, des Werts und der Anzeige:
Datenübertragung | Initialisierung | |
Datenfeld aus USING-Angabe in IDENTIFIED-Klausel | Name des Knotens aus dem Baum | Leerzeichen |
Datenfeld für den Wert | Wert des Knotens aus dem Baum | initialisiert mittels |
Datenfeld aus COUNT-Klausel | 1 | 0 |
Beispiel 12-42 Sequenzielles Lesen
XML-Dokument | Pos | COBOL-Datenstruktur |
|
|
|
|
| 1 2 3 4 |
| 1(o) 2(o) | 1(o) 2(r) a 111 | 1(o) 3(r) b 222 | 1(o) at-end b 222 |
| 00 | 00 | 08 | 10 |
Anmerkungen:
Hinweise zur Darstellung dieses Beispiels finden Sie auf "Anweisungen für die XML-Verarbeitung".
Für das Lesen über y ist die erfolgreiche Zuordnung eines Knotens (Knoten 2) durch die OPEN DOCUMENT-Anweisung ausreichend. Es ist nicht notwendig, dass in der 01-Struktur übergeordnete Datenfelder (x) bereits gelesen wurden.
Das Lesen über y erfolgt sequenziell, da IDENTIFIED USING angegeben ist.
Die dem y zugeordnete Position vor der ersten READ-Anweisung wurde durch eine OPEN DOCUMENT-Anweisung gesetzt. Als Wirkungsbereich kommen dementsprechend die Teilbäume mit Wurzeln Knoten2 und 3 (in dieser Reihenfolge) in Frage. Knoten 2 wird zugeordnet sowie Name und Wert des gelesenen Knotens übertragen.
Einem Datenfeld mit IDENTIFIED-Klausel darf nur ein einziges Datenfeld direkt untergeordnet sein, das nicht in der IDENTIFIED-Klausel angesprochen wird: In dieses Feld (y-wert) wird der Wert des zugeordneten Knoten übertragen.
Wenn der Wert eines Knoten für das Programm ohne Bedeutung ist, kann das Datenfeld dafür auch ganz entfallen, wie bei Datenfeld x.-
Nach der ersten READ-Anweisung ist y weiterhin der Knoten 2 zugeordnet. Die Position vermerkt jedoch, dass sie durch READ entstanden ist. Für die Zuordnung bei der folgenden READ-Anweisung kommen nur jüngere Geschwister, d.h. Knoten 3, in Frage.
Bei der zweiten READ-Anweisung enthält der zugeordnete Teilbaum einen Knoten (c), der in der entsprechenden COBOL-Struktur y nicht beschrieben ist. Das zeigt der Ein-/Ausgabe-Zustand 08 an.
Bei der dritten READ-Anweisung hat der zugeordnete Knoten 3 keine jüngeren Geschwister, also entsteht die Ende-Bedingung. Die Datenfelder für Name und Wert bleiben unverändert.
Beispiel 12-43 Wahlfreies Lesen und Wiederholungen
XML-Dokument | Pos | COBOL-Datenstruktur |
|
|
|
|
| 1 2 3 4 5 |
| 1(o) 3(o) a | 1(o) 3(r) a 222 | 1(o) 4(r) a 333 | 1(o) at-end a 333 |
| 00 | 00 | 00 | 10 |
Anmerkungen:
Hinweise zur Darstellung dieses Beispiels finden Sie auf "Anweisungen für die XML-Verarbeitung".
Das Lesen über y erfolgt wahlfrei, da IDENTIFIED BY angegeben ist. Aktueller Wert des Schlüssels ist 'a'.
Die dem y zugeordnete Position bei der ersten READ-Anweisung wurde durch eine OPEN DOCUMENT-Anweisung gesetzt. Also kommen als Wirkungsbereich die Teilbäume mit Wurzeln Knoten 3, 4 und 5 in Frage. Als erster davon lässt sich Knoten 3 zuordnen.
Nach der ersten READ-Anweisung ist y weiterhin der Knoten 3 zugeordnet. Die Position vermerkt jedoch jetzt, dass sie durch READ entstanden ist.
Der Wirkungsbereich der zweiten READ-Anweisung umfasst die Teilbäume mit Wurzeln Knoten4 und 5. Davon lässt sich Knoten 4 zuordnen. Da Knoten 3 nicht mehr Teil des Wirkungsbereichs ist, liest diese READ-Anweisung die Wiederholung, d.h. das zweite Exemplar des Knotens mit Namen 'a'.
Bei der dritten READ-Anweisung hat der zugeordnete Knoten4 zwar noch ein jüngeres Geschwister (Knoten 5). Es ist jedoch wegen des nicht übereinstimmenden Namens keine Zuordnung möglich.
Bei wahlfreiem Lesen entsteht ggf. auch eine Ende-Bedingung.
Beispiel 12-44 Wahlfreies Lesen mit wechselndem Schlüsselwert
XML-Dokument | Pos | COBOL-Datenstruktur |
|
|
| |
| 1 2 3 4 5 |
| 1(o) 3(o) a | 1(o) 3(r) a 222 | MOVE | 1(o) 5(r) c 444 |
Anmerkungen:
Hinweise zur Darstellung dieses Beispiels finden Sie auf "Anweisungen für die XML-Verarbeitung".
Bis einschließlich der ersten READ-Anweisung besteht kein Unterschied zum vorhergehenden Beispiel.
Der Wirkungsbereich der zweiten READ-Anweisung umfasst wie im vorhergehenden Beispiel die Teilbäume mit Wurzeln Knoten 4 und 5. Die Änderung des Werts von Schlüssel y-name zu 'c' bewirkt jetzt die Zuordnung von Knoten 5.
Da die OPEN DOCUMENT-Anweisung mit dem Schlüsselwert 'a' ausgeführt wurde, kann Knoten 2 trotz des danach modifizierten und eigentlich passenden Schlüsselwerts 'c' nie mehr durch Lesen über y erreicht werde. Das Öffnen hat y den Knoten 3 zugeordnet. Daher kommen für alle weiteren READ-Anweisungen nur mehr dieser Knoten und seine jüngeren Geschwister als Wirkungsbereich in Frage, jedoch nicht das ältere Geschwister Knoten 2.
Beispiel 12-45 Wirkung von wechselnden Schlüsselwerten
XML-Dokument | Pos | COBOL-Datenstruktur |
|
|
| |
| 1 2 3 4 5 6 7 |
| 1(o) 2(o) a 3(o) c | MOVE MOVE | 1(o) 2(o) b 4(r) d 444 | 1(o) 5(r) b 555 7(r) d 777 |
Anmerkungen:
Hinweise zur Darstellung dieses Beispiels finden Sie auf "Anweisungen für die XML-Verarbeitung".
Änderungen von Schlüsselwerten (y-name und z-name) nach einer erfolgreichen Zuordnung nach der OPEN DOCUMENT-Anweisung wirken sich nicht immer auf nachfolgende Zuordnungen aus.
Die beiden MOVE-Anweisungen nach OPEN DOCUMENT legen nahe, dass die erste READ-Anweisung wahlfrei auf den Teilbaum mit Wurzel Knoten 5 (Name = 'b') und darin auf den Knoten 7 (Name = 'd') zugreifen soll: Das Lesen über Datenfeld z ist für diesen Zweck jedoch nicht geeignet.
Werte von Schlüsseln, die in der COBOL-Struktur dem beim Lesen verwendeten Schlüssel (z mit z-name) übergeordnet sind (y mit y-name), werden bei einer Zuordnung nicht berücksichtigt. Änderungen solcher Schlüsselwerte bleiben wirkungslos. Im Beispiel erfolgt der Zugriff weiterhin im zugeordneten Teilbaum mit Wurzel 2 und darin auf Knoten 4.
Neben der Änderung der Schlüsselwerte ist auch über ein Datenfeld zu lesen, das kei-nem der geänderten Schlüssel untergeordnet ist, wie Datenfeld y in der zweiten READ-Anweisung.
Beispiel 12-46 Übertragene Daten
XML-Dokument | Pos | COBOL-Datenstruktur |
|
|
| 1 2 3 4 |
| 1(o) 3(o) 2(o) inv | 1(r) 000 3(r) pq 2(r) 1 02200 inv 0
|
Anmerkungen:
Hinweise zur Darstellung dieses Beispiels finden Sie auf "Anweisungen für die XML-Verarbeitung".
Beim wahlfreien Lesen spielt die Reihenfolge der Datenfelder in der COBOL-Struktur – zuerst y für Knoten mit Namen 'b', dann z für Knoten mit Namen 'a' – und die der zugeordneten Knoten im Baum – erst der mit Name 'a', dann der mit Name 'b' – keine Rolle.
Nicht-numerische Werte aus dem Baum, die zu kurz sind, werden mit Leerzeichen aufgefüllt (x-wert), Werte die zu lang sind, werden abgeschnitten (y-wert).
Numerische Werte werden dezimalpunktgerecht übertragen (z-wert), ggf. auch in eine andere USAGE konvertiert.
Die COUNT-Datenelemente zeigen an, ob einem Datenfeld Knoten zugeordnet werden konnten (z-count) oder nicht (u-count). Nur die READ-Anweisung setzt diese Anzeige.
Klein-/Großschreibung der Schlüsselwerte spielt eine Rolle. Daher wird Knoten 4 mit Namen 'c' nicht dem Datenfeld u mit Schlüsselwert 'C' zugeordnet.
Datenfelder, die demjenigen über das gelesen wurde (x) untergeordnet sind und denen kein Knoten zugeordnet wurde (u), bekommen ungültige Positionen im EPV und werden initialisiert.
Beispiel 12-47 Elemente und Attribute
XML-Dokument | Pos | COBOL-Datenstruktur |
|
|
|
|
|
| 1 |
| | |
|
|
|
| 00 | 08 | 00 | 00 | 10 |
Anmerkungen:
Hinweise zur Darstellung dieses Beispiels finden Sie auf "Anweisungen für die XML-Verarbeitung".
Die OPEN DOCUMENT-Anweisung ordnet gleichzeitig sowohl Element-Knoten, als auch Attribut-Knoten zu.
Bei vorgegebenen Schlüsseln wird dem Attribut x-att1 (Schlüssel='d2') der Knoten 3 zugeordnet. Dem Attribut x-att2 (Schlüssel='d3') kann kein Knoten zugeordnet werden. Ohne vorgegebene Schlüssel wird dem Attribut y-att der erste Attribut-Knoten zugeordnet (Knoten 5).
Die COUNT-Klausel ist auch für Attribute möglich (x-att2).
Das nicht in der COBOL-Struktur beschriebene Attribut d2 bewirkt beim Lesen über x den Ein-/Ausgabe-Zustand 08.
Auch für das sequenzielle Lesen von Attributen gilt die Regelung mit dem Wirkungsbereich, selbst wenn dabei die Teilbäume nur aus einem Knoten bestehen. Der Wirkungsbereich der zweiten READ-Anweisung umfasst die Knoten 6 und 7. Da bei sequenziellem Zugriff jeder Name passt, wird also Knoten 6 zugeordnet.
Es ist nicht notwendig, über ein Datenfeld sequenziell bis zum Ende zu lesen, z.B. auch noch 'a3' über y-att. Es darf bereits vorher zu einem anderen Datenelement gewechselt werden (y).
Die dritte READ-Anweisung (über y) ordnet y den Knoten 8 zu und dem untergeordneten Attribut (y-att) das erste Attribut 'a1' dieses Knotens (Knoten9).
Ein erreichtes Ende beim sequenziellen Lesen wird im EPV entsprechend vermerkt (für Datenfeld y). In diesem Fall werden die EPV-Einträge von allen untergeordneten Datenfeldern auf ungültig gesetzt (y-att). Die Werte der Datenfelder bleiben jedoch unverändert (y-name, y-wert, y-att-name, y-att-wert).
Die Angabe von BY (x-att1) und USING (y) für Datenfelder mit der selben unmittelbar übergeordneten Datengruppe (x) ist zulässig, weil sie unterschiedliche Arten von Knoten beschreiben (Attribut bzw. Element).-
Beispiel 12-48 Wahlfreies Lesen von Attributen
XML-Dokument | Pos | COBOL-Datenstruktur | OPEN DOCUMENT xml-fil | READ ATTRIBUTE y-att READ | READ ATTRIBUTE y-att | READ ATTRIBUTE y-att | |
| 1 2 3 4 5 |
| 1(o) 2(o) 4(o) a2 | 1(o) 2(o) 4(r) a2 002 | 1(o) 2(o) 4(r) a2 002 | MOVE | 1(o) 2(o) 3(r) a1 001 |
Anmerkungen:
Hinweise zur Darstellung dieses Beispiels finden Sie auf "Anweisungen für die XML-Verarbeitung".
Die erste READ-Anweisung ordnet y-att das Attribut Knoten 4 mit dem vorgegebenen Schlüssel 'a2' zu.
Die zweite READ-Anweisung zum wahlfreien Lesen eines Attributs untersucht – wegen des unveränderten Schlüssels – daher die Knoten 3, 4 und 5 auf mögliche Zuordnung, d.h. den schon zugeordneten Knoten und alle seine Geschwister: Sie ordnet erneut Knoten 4 zu.
Da beim wahlfreien Lesen von Attributen (im Gegensatz zur ELEMENT-Angabe, vgl. Beispiel „Wahlfreies Lesen und Wiederholungen") alle Knoten betrachtet werden, kann bei unverändertem (und im Baum vorhandenem) Schlüssel nie die EndeBedingung auftreten.
Da beim wahlfreien Lesen von Attribut-Knoten alle Geschwister-Knoten betrachtet werden, lassen sich durch Änderung des Schlüsselwerts (zu 'a1') mit der dritten READ-Anweisung auch ältere Geschwister (Knoten 3) des dem Datenfeld y-att zugeordneten Knotens (Knoten 4) lesen.
Beispiel 12-49 Mehrfaches Lesen des gleichen Knotens
XML-Dokument | Pos | COBOL-Datenstruktur |
|
|
|
|
| 1 2 3 4 5 |
| 1(o) 2(o) 3(o) | 1(o) 2(o) 3(r) c 333 | 1(o) 2(o) 4(r) d 444 | 1(o) 2(r) a 222 3(r) c 333 |
Anmerkungen:
Hinweise zur Darstellung dieses Beispiels finden Sie auf "Anweisungen für die XML-Verarbeitung".
Daten zu Knoten 3 werden durch das Lesen über z geliefert. Die zweite READ-Anweisung setzt die Position von z auf Knoten 4.
Für das anschließende Lesen über das übergeordnete Datenfeld y spielt nur die dem y selber zugeordnete Position (Knoten 2) eine Rolle. Die Positionen von untergeordneten Datenfeldern (z) sind ohne Bedeutung.
Entsprechend dem Zuordnungsverfahren ordnet die dritte READ-Anweisung dem z dann erneut den Knoten3 zu und liefert auch dessen Daten (nicht die von Knoten 5).
Eingeschränkte Datenübertragung mit ONLY
READ erlaubt optional die Angabe von ONLY vor dem Schlüsselwort ELEMENT: In diesem Fall werden nur Daten in Verbindung mit dem in der READ-Anweisung angegebenen Datenfeld übertragen, einschließlich ggf. vorhandener Attribute. Für alle anderen untergeordneten Datenfelder unterbleibt eine Datenübertragung. Die Zuordnung von Knoten erfolgt jedoch auch für die untergeordneten Datenfelder. Da für die untergeordneten Datenfelder noch keine Daten übertragen wurden, ist ihr EPV-Eintrag bei späteren lesenden Zugriffen so zu interpretieren, als ob er durch eine OPEN DOCUMENT-Anweisung entstanden wäre.
Für das Lesen von Attributen ist ONLY verboten und macht auch keinen Sinn, da AttributKnoten keine Kinder haben.
Beispiel 12-50 Eingeschränkte Datenübertragung mit ONLY
XML-Dokument | Pos | COBOL-Datenstruktur |
|
|
|
|
|
| 1 2 3 4 5 6 7 8 9 |
| 1(o) 2(o) 4(o) 3(o) | 1(o) 2(r) 2 4(r) b 4 3(r) A | 1(o) 2(r) 2 5(r) c 5 3(r) A | 1(o) 6(r) 6 8(o) c 5 7(r) B | 1(o) 6(r) 6 8(r) b 8 7(r) B |
Anmerkungen:
Hinweise zur Darstellung dieses Beispiels finden Sie auf "Anweisungen für die XML-Verarbeitung".
Die erste READ-Anweisung liest den Knoten 2 mit seinem Attribut Knoten 3, sowie den untergeordneten Knoten 4. Die nachfolgende READ-Anweisung über das untergeordnete Datenfeld z liest sequenziell den nächsten Knoten 5.
Zum Vergleich das Lesen im analog strukturierten Teilbaum mit Wurzel 6, jedoch mit ONLY-Angabe, d.h. ohne Übertragung der untergeordneten Elemente: Für das Datenfeld y aus der READ-Anweisung werden der Name und Wert des Elements übertragen ('a' und '6'). Für die ihm untergeordneten Datenfelder, die Attribut-Knoten beschreiben (y-att), erfolgt ebenfalls die Datenübertragung ('B').
Für die dem y untergeordneten Datenfelder, die Element-Knoten (hier nur z) beschreiben, werden zwar Knoten zugeordnet (Knoten 8), aber keine Daten übertragen. In der COBOL-Struktur vorhandene Daten bleiben unverändert. Die Zuordnung im EPV vermerkt, dass sie nicht durch READ erfolgte.
Die anschließende vierte READ-Anweisung über das untergeordnete Datenfeld (z) überträgt jetzt erst Name und Wert des zugeordneten Knoten 8, nicht wie die zweite READ-Anweisung Name und Wert des folgenden Knoten.
Zusammenfassung
Zusammenfassend ist bei der READ-Anweisung Folgendes zu beachten:
Wahlfreier lesender Zugriff auf Elemente erlaubt immer nur einen Zugriff auf Kinder und jüngere Geschwister, dagegen nie auf Väter oder ältere Geschwister.
Wahlfreies Lesen, ohne zwischenzeitliche OPEN- bzw. START-Anweisung oder Änderung des Schlüssels, liefert bei Element-Knoten die Wiederholungen und nach dem letzten Exemplar die Ende-Bedingung. Bei Attribut-Knoten wird immer wieder das gleiche (einzige) Exemplar geliefert.
Durch eingeschobene, untergeordnete Elemente aufgesplitterte Werte werden zu einem einzigen Stück zusammengefasst geliefert.
Eine READ-Anweisung ohne ONLY-Angabe liefert für den Ein-/Ausgabe-Zustand den Wert 08, wenn es in dem für die Zuordnung verwendeten Teilbaum mindestens einen Knoten unterhalb der Wurzel gibt, der nie einem Datenfeld in der COBOL-Struktur zugeordnet werden kann.
Es geht hier um die prinzipielle Möglichkeit, den Knoten einem Datenfeld zuordnen zu können. Das hat nichts damit zu tun, ob bei der aktuellen READ-Anweisung diese Zuordnung erfolgt ist und Daten übertragen wurden. Insbesondere bedeutet das: Wiederholungen von Elementnamen im Baum, von denen ein Exemplar zugeordnet werden konnte, bewirken keinen Wert 08 für den Ein-/Ausgabe-Zustand.
Bei einer READ-Anweisung mit ONLY-Angabe kann es den Ein-/Ausgabe-Zustand 08 nur für nicht zuordenbare Attribute des gelesenen Elements geben, nicht jedoch für andere Knoten des betrachteten Teilbaums.
Aktuelle Positionen bzw. zugeordnete Knoten für Datenfelder, die dem in der READ-Anweisung angegebenen Datenfeld in der COBOL-Struktur untergeordnet sind, spielen keine Rolle.
Das in der READ-Anweisung angegebene Datenfeld bestimmt gleichzeitig, wo gesucht/gelesen werden soll und was gesucht/gelesen werden soll.
Eine READ-Anweisung ist meist eine Mischung aus sequenziellem und wahlfreiem Zugriff, wobei auf alle Element-Kinder bzw. Attribut-Kinder eines Knotens auf die gleiche Art zugegriffen wird, unabhängig davon, auf welche Art auf den Knoten selbst zugegriffen wird.
Eine READ-Anweisung ändert im EPV nur die Position des Datenfeldes, über das gelesen wird, und der ihm untergeordneten Datenfelder. Die Positionen aller anderen Datenfelder bleiben unverändert.