Funktion
Die IDENTIFIED-Klausel legt fest, welche Element- bzw. Attributnamen aus dem XML-Dokument sich einem COBOL-Datenfeld zuordnen lassen. Die NAMESPACE-Angabe legt die dabei zu berücksichtigenden Namensräume fest.
Format
IDENTIFIED {BY {datenname-1 | literal-1} | USING datenname-2} IS {ATTRIBUTE | ELEMENT}
[ NAMESPACE {IS {datenname-3 | literal-2 | NULL} | USING datenname-4}]
Syntaxregeln
Die IDENTIFIED-Klausel darf nur in Satzbeschreibungen von XML-organisierten Dateien angegeben werden.
Alle der Datenerklärung übergeordneten Datengruppen müssen ebenfalls eine IDENTIFIED-Klausel enthalten.
literal-1 und literal-2 müssen alphanumerische oder nationale Literale, jedoch keine figurativen Konstanten sein.
literal-1 muss ein gültiger XML-Name für ein Element bzw. Attribut sein.
literal-2 muss ein gültiger XML-Name für einen Namensraum sein.
datenname-1, datenname-2, datenname-3 und datenname-4 dürfen gekennzeichnet sein.
datenname-1, datenname-2, datenname-3 und datenname-4 müssen alphanumeri-sche oder nationale Datenfelder sein. Ihre Datenerklärung darf keine IDENTIFIED-Klausel angeben.
Wenn datenname-1, datenname-2, datenname-3 und datenname-4 innerhalb einer Satzbeschreibung einer XML-organisierten Datei definiert sind, müssen sie dem Eintrag mit der IDENTIFIED-Klausel, die sie anspricht, direkt untergeordnet sein.
Einer Datenerklärung mit ATTRIBUTE-Angabe dürfen keine Datenerklärungen mit einer IDENTIFIED-Klausel untergeordnet sein.
Einer Datenerklärung mit IDENTIFIED-Klausel darf höchstens ein Datenfeld direkt untergeordnet sein, das weder in der IDENTIFIED-Klausel angesprochen wird, noch selbst eine IDENTIFIED-Klausel enthält.
Die nachstehende Tabelle gibt an, welche Kombinationen von Angaben zum Element- bzw. Attributnamen und Angaben zum Namensraum innerhalb einer IDENTIFIED-
Klausel erlaubt sind.IDENTIFIED
NAMESPACE
IS
NULLIS
datenname-3 /
literal-2USING
datenname-4BY datenname-1 / literal-1
erlaubt
erlaubt
verboten
USING datenname-2
erlaubt
verboten
erlaubt
Tabelle 43: Erlaubte Kombination von IDENTIFIED- und NAMESPACE-Angabe in einer IDENTIFIED-Klausel
Wenn einer Datengruppe mehrere Datenerklärungen direkt untergeordnet sind, die die ELEMENT-Angabe machen, unterliegen die möglichen Angaben zu IDENTIFIED und NAMESPACE weiteren Einschränkungen. Gleiches gilt für Datenerklärungen, die die ATTRIBUTE-Angabe machen. Die nachstehende Tabelle gibt an, welche Kombinationen bei je zwei Datenerklärungen erlaubt sind. Die grau unterlegten Zeilen und Spalten stellen Kombinationen dar, die schon für eine einzelne Datenerklärung nicht erlaubt sind.
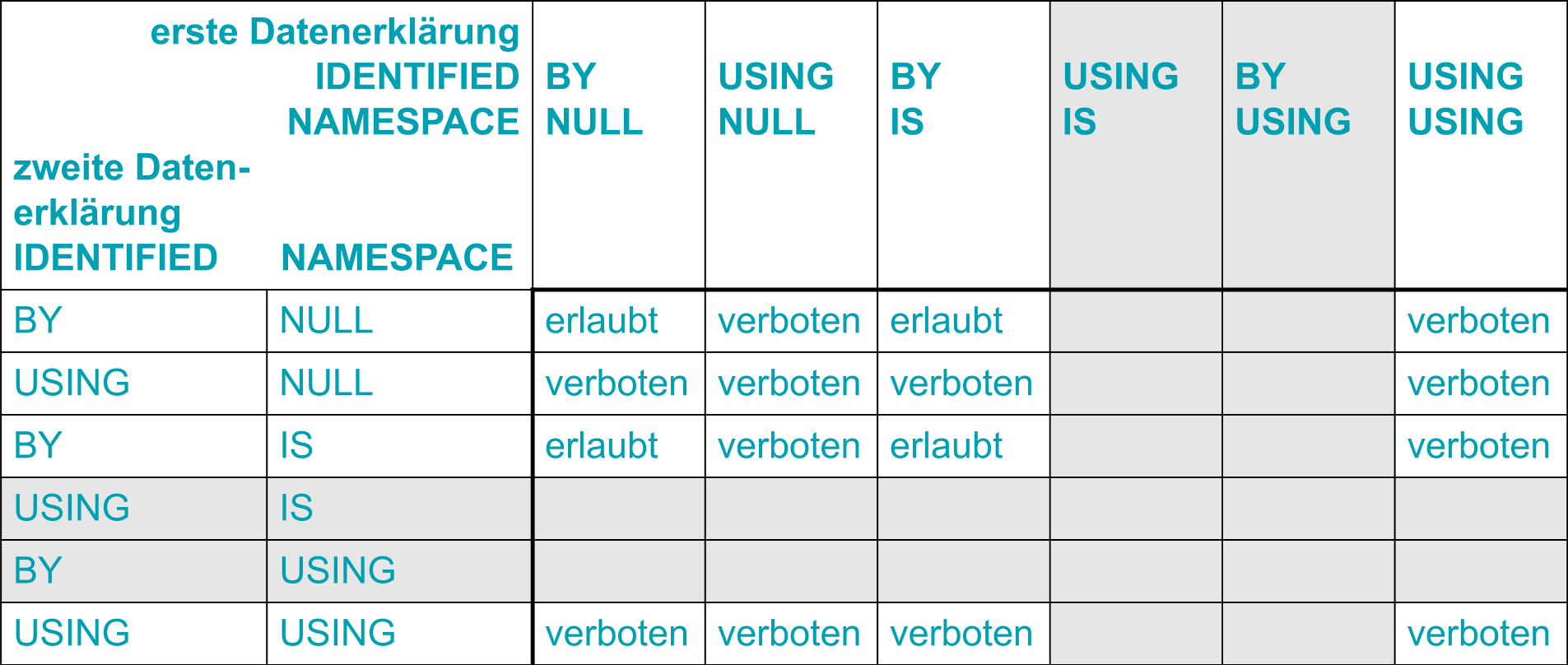
Tabelle 44: Erlaubte Kombination von zwei Datenerklärungen mit IDENTIFIED- und NAMESPACE-Angaben
Wenn einer Datengruppe mehrere Datenerklärungen direkt untergeordnet sind, die alle die gleiche explizite oder implizite NAMESPACE-Angabe machen, dann müssen
für alle, die explizit oder implizit die ELEMENT-Angabe machen, deren Werte von literal-1 eindeutig sein.
für alle, die die ATTRIBUTE-Angabe machen, deren Werte von literal-1 eindeutig sein.
Dabei spielen für die Eindeutigkeit weder die Darstellung als alphanumerisches oder nationales Literal noch endständige Leerzeichen eine Rolle.
Wenn ATTRIBUTE nicht angegeben ist, wird ELEMENT angenommen.
Die IDENTIFIED-Klausel darf nicht innerhalb einer Typdeklaration verwendet werden.
Allgemeine Regeln
Die IDENTIFIED-Klausel beschreibt, welche Knoten aus dem XML-Dokument dem Datenfeld zugeordnet werden sollen:
Wenn ELEMENT angegeben ist, werden nur Element-Knoten zugeordnet.
Wenn ATTRIBUTE angegeben ist, werden nur Attribut-Knoten zugeordnet.
Bei Angabe von BY legen literal-1 bzw. der Inhalt von datenname-1 den Namen fest, den der zugeordnete Knoten haben soll. Dabei spielen weder die Darstellung als alphanumerisches oder nationales Literal bzw. Datenfeld noch endständige Leerzeichen eine Rolle.
Bei Angabe von IS legen literal-2 bzw. der Inhalt von datenname-3 den Namensraum fest, den der zugeordnete Knoten haben soll. Dabei spielen weder die Darstellung als alphanumerisches oder nationales Literal bzw. Datenfeld noch endständige Leerzeichen eine Rolle.
Bei Angabe von USING dürfen die zugeordneten Knoten beliebige Namen haben bzw. in beliebigen Namensräumen liegen. Bei erfolgreichem Lesen werden die Namen solcher Knoten in datenname-2 bzw. der zugehörige Namensraum in datenname-4 übertragen.
Eine Zuordnung eines Knotens zu einem Datenfeld ist nur möglich, wenn allen ihm in der Struktur übergeordneten Datenfeldern auch ein Knoten zugeordnet ist.
Die NAMESPACE-Angabe legt den Namensraum fest für einen Eintrag sowie für alle ihm untergeordneten Datenfelder, die eine IDENTIFIED-Klausel mit expliziter oder impliziter ELEMENT-Angabe haben.
Wenn ein untergeordnetes Datenfeld ebenfalls eine NAMESPACE-Angabe hat, hat diese Angabe Vorrang vor einer NAMESPACE-Angabe der übergeordneten Datengruppe.
NAMESPACE NULL bedeutet eine leere Zeichenfolge als Namensraum. Wenn die NAMESPACE-Angabe fehlt, und wenn auch keine übergeordnete Datengruppe eine NAMESPACE-Angabe hat, wird NAMESPACE NULL angenommen.
Wenn eine OPEN DOCUMENT-, READ- oder START-Anweisung eine Datengruppe anspricht, muss für diese und alle ihr untergeordneten Datengruppen Folgendes erfüllt sein:
Wenn einer Datenerklärung, die der Datengruppe direkt untergeordnet ist, ein Knoten aus dem XML-Baum zugeordnet werden kann (siehe "Zuordnen von Knoten"), muss diese Zuordnung eindeutig sein. D.h. es darf keine weitere, der Da-tengruppe direkt untergeordnete Datenerklärung geben, der der Knoten aus dem XML-Baum ebenfalls zugeordnet werden könnte.
Dabei spielen für die Eindeutigkeit weder die Beschreibung der Namen der Knoten als alphanumerisches oder nationales Literal bzw. Datenfeld eine Rolle, noch endständige Leerzeichen. Wenn die Eindeutigkeit nicht gegeben ist, ist die Anweisung nicht erfolgreich und der Ein-/Ausgabe-Zustand der Datei wird auf 4C gesetzt.
Es ist immer die komplette Bezeichnung für den Namensraum, der Uniform Resource Identifier (URI), bereitzustellen, bzw. wird er zurückgeliefert. Die in XML verwendeten Präfixe sind in COBOL nicht sichtbar.
Namensraumdeklarationen haben im XML-Dokument zwar die Form eines Attributs, sie werden jedoch nicht als Attribute geliefert, selbst wenn sie in einer IDENTIFIED-Klausel entsprechend beschrieben sind.