Mit diesem Format der @ON-Anweisung kann vor oder nach einer Trefferzeichenfolge in Arbeitsdateizeilen bzw. Zeichenfolgevariablen Text eingefügt oder ersetzt werden.
Operation | Operanden | F-Modus, L-Modus |
@ON | { lines | svars } [,...] [:cols[:] ] FIND [ALL] [F] [R] [PATTERN] | |
lines svars | Einer oder mehrere Zeilenbereiche, in denen gesucht werden soll. Einer oder mehrere Bereiche von Zeichenfolgevariablen, in denen gesucht |
cols | Zusammenhängender Spaltenbereich, auf den die Suche eingeschränkt Enthält die Bereichsangabe nur eine einzelne Spaltenangabe, so wird damit Wird kein Spaltenbereich angegeben, wird der mit @SEARCH-OPTION |
ALL | Bei einer Texteinfügung wird vom EDT vor bzw. hinter allen Trefferzeichenfolgen Bei einer Textersetzung wird vor bzw. hinter allen Trefferzeichenfolgen einer Falls bei der Suche von links nach rechts der Text hinter einer Trefferzeichenfolge |
Ist | |
F | In jedem angegebenen Zeilenbereich wird das Ersetzen bzw. das Einfügen |
R | Die Zeilen werden von rechts nach links durchsucht. Ist |
PATTERN search | Die im Suchbegriff vorkommenden Musterzeichen werden interpretiert. Suchbegriff, der im Suchbereich aufgefunden werden soll (Details siehe |
int | Erst das |
CHANGE | Der vor oder nach der Trefferzeichenfolge stehende Text bis zum Satzanfang |
INSERT | Die mit |
PREFIX | Die mit |
SUFFIX | Die mit |
string | Zeichenfolge, die den Text vor oder nach der Trefferzeichenfolge ersetzen Die Zeichenfolge wird in den Zeichensatz der Arbeitsdatei bzw. der Die Zeichenfolge |
Das Ersetzen bzw. das Einfügen findet nicht statt, wenn ein Satz dadurch die maximale Satzlänge von 32768 Zeichen überschreitet. Stattdessen wird in diesem Falle die Meldung EDT1937 ausgegeben, die Abarbeitung aber fortgesetzt.
Wird die Anweisung mit [K2] unterbrochen und der EDT-Lauf mit /INFORM-PROGRAM fortgesetzt, so wird die Bearbeitung der Anweisung abgebrochen und die Meldung EDT5501 ausgegeben.
Beispiel 1

Alle mehrfachbenutzbaren Dateien der Benutzerkennung USER2, die mit dem teilqualifizierten Namen BSP. beginnen, sollen aufgelistet werden.

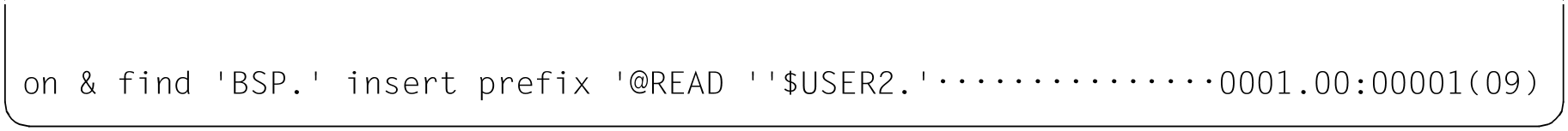
Jedem teilqualifizierten Namen BSP. soll die Zeichenfolge @READ '$USER2. vorangestellt werden.


Das abschließende Hochkomma wird hinter den vier Dateinamen $USER2.BSP.1 bis $USER2.BSP.4 eingefügt.


Die vier Dateien BSP.1 bis BSP.4 werden hintereinander in die Arbeitsdatei 1 eingelesen.
Beispiel 2


Im Zeilenbereich 1 bis 2 soll von rechts nach links nach dem dritten Auftreten der Zeichenfolge 11 gesucht und im Trefferfall dahinter ++++ eingefügt werden.


In Zeile 1 trat der Suchbegriff zum dritten Mal von rechts in den Spalten 17-18 auf.
In Zeile 2 trat der Suchbegriff zum ersten Mal in den Spalten 24-25, zum zweiten Mal in den Spalten 22-23 und zum dritten Mal in den Spalten 19-20 auf. Hinter dem Treffer wurde die Zeichenfolge ++++ eingefügt.
Nun soll in der gesamten Arbeitsdatei ab Spalte 4 nach dem dritten Auftreten der Zeichenfolge 111 gesucht werden. Im Trefferfall ist der nachfolgende Text zu ersetzen durch ####.

In Zeile 1 trat der Suchbegriff nicht auf.
In Zeile 2 trat der Suchbegriff beginnend ab Spalte 4 zum ersten Mal in den Spalten 7-9,
zum zweiten Mal in den Spalten 12-14 und zum dritten Mal als Treffer in den Spalten 17-19
auf. Nach dem Treffer wurde der Zeilenrest durch die Zeichenfolge #### ersetzt.