Qualifizierte Namen in XML-Dokumenten setzen sich zusammen aus einem lokalen Namen und einem Namensraum, innerhalb dessen der lokale Name eindeutig sein muss. Der Namensraum wird wie ein Attribut bei einem Element angegeben:
Er kann einen Standard-Namensraum festlegen:
xmlns="..."
Dieser Standard-Namensraum gilt für dieses Element und alle untergeordneten, sofern dort kein anderer Namensraum in einem Elementnamen angegeben ist, nicht jedoch für Attribute.Er kann ganz ausgeschaltet werden:
xmlns=""
Dieser leere Namensraum gilt ebenfalls für dieses Element und alle untergeordneten, sofern dort nichts anderes angegeben ist.Er kann eine Abkürzung (Präfix) für einen (Nicht-Standard-)Namensraum definieren:
xmlns:präfix="..."
Dies ist auch mehrfach erlaubt, mit unterschiedlichen Präfixen, um über mehrere Namensräume verfügen zu können.
Ein solches Präfix darf in diesem Element, allen ihm untergeordneten Elementen und auch den Attributen dieser Elemente den lokalen Namen vorangestellt werden, um einen eindeutigen, qualifizierten Namen zu bilden, in der Formpräfix:lokalername.
Die in der IDENTIFIED-Klausel aufgeführten Element- bzw. Attributnamen beschreiben immer den lokalen Namen. Der Verarbeitung von Namensräumen aus dem XML-Dokument dient die optionale NAMESPACE-Angabe in der IDENTIFIED-Klausel. Sie erlaubt es, für das beschriebene Element bzw. Attribut:
einen gewünschten Namensraum vorzugeben:
NAMESPACE IS {datenname-3 | literal-2}beliebige Namensräume zu akzeptieren: NAMESPACE USING datenname-4
Die Wirkung entspricht der USING-Angabe bei IDENTIFIED: In datenname-4 wird der gelesene Namensraum zurückgeliefert.den leeren Namensraum festzulegen: NAMESPACE IS NULL
Die implizite Wirkung von Namensräumen für untergeordnete Elemente eines XML-Dokuments findet sich analog in COBOL wieder:
Die NAMESPACE-Angabe einer IDENTIFIED-Klausel gilt für das angegebene Datenfeld und vererbt sich auf alle untergeordneten Datenfelder mit IDENTIFIED-Klausel und ELEMENT-Angabe, jedoch nicht auf Datenfelder mit ATTRIBUTE-Angabe.
Wenn ein untergeordnetes Datenfeld selbst eine NAMESPACE-Angabe macht, hat diese Vorrang vor einer evtl. geerbten.
Wenn auf Stufe 01 in einer IDENTIFIED-Klausel die NAMESPACE-Angabe fehlt, ist das gleichbedeutend mit der Angabe NAMESPACE NULL.
Die Präfixe, welche als Abkürzung in der XML-Notation möglich sind, haben mit dem NAMESPACE in COBOL nichts zu tun. Sie sind in COBOL nicht sichtbar.
Als Wert eines Namensraums verwenden die COBOL-Anweisungen immer den 'kompletten' Wert aus der xmlns-Angabe im XML-Dokument, nie das Präfix.
Die Unterscheidung auf der XML-Seite zwischen Standard-Namensraum und mit Präfixen explizit angegebenen Namensräumen ist auf der COBOL-Seite ohne Bedeutung, da hier keine Präfixe existieren.
Die möglichen Kombinationen der Angaben von BY bzw. USING bei lokalen Namen und Namensräumen unterliegen bestimmten Einschränkungen. Dabei spielt es keine Rolle, ob die NAMESPACE-Angabe explizit gemacht wurde oder implizit gilt. Die Einschränkungen betreffen einerseits die Angaben innerhalb einer einzigen IDENTIFIED-Klausel. Anderer-seits betreffen Sie die Kombination von zwei oder mehr Datenerklärungen mit IDENTIFIED-Klausel der gleichen Art (ELEMENT bzw. ATTRIBUTE), sofern sie in der COBOL-Struktur dem gleichen Datenfeld direkt untergeordnet sind.
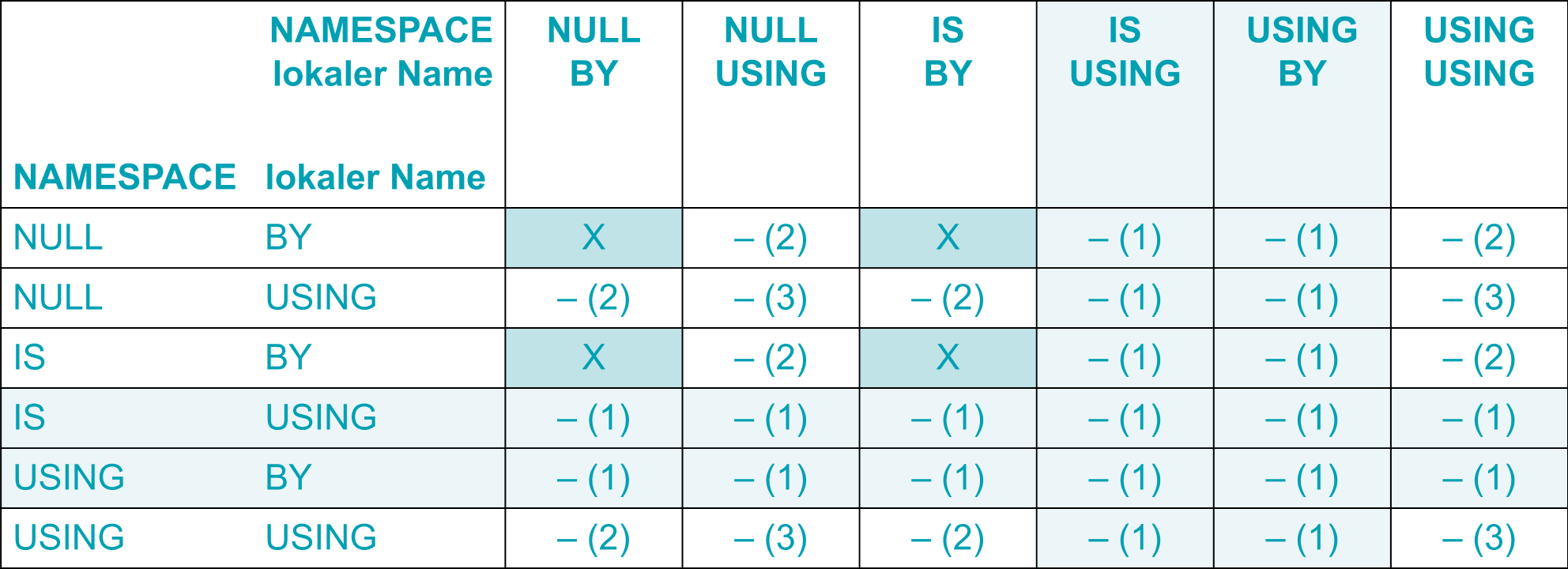
Die nachfolgende Tabelle gibt einen Überblick über erlaubte Kombinationen der Angaben von BY bzw. USING innerhalb einer IDENTIFIED-Klausel mit beliebiger Angabe der Art (ELEMENT oder ATTRIBUTE):

Die nachfolgende Tabelle gibt einen Überblick über erlaubte Kombinationen der Angaben von BY bzw. USING bei zwei Datenerklärungen mit IDENTIFIED-Klauseln mit gleicher An-gabe der Art. D.h. die Verbote gelten jeweils nur innerhalb der Menge von IDENTIFIED-Klauseln, die alle die ELEMENT- bzw. alle die ATTRIBUTE-Angabe machen. Für Mischungen gibt es keine Einschränkungen. Es ist also zulässig, einem Datenfeld zwei Datenfelder mit IDENTIFIED BY...ATTRIBUTE und IDENTIFIED USING...ELEMENT direkt unterzuordnen.
(1) | IDENTIFIED-Klausel für sich bereits ungültig |
(2) | ungültig wegen Kombination von BY mit USING |
(3) | mehr als eine IDENTIFIED-Klausel mit USING ungültig |
Das oben beschriebene Verfahren der Zuordnung ist durch Namensräume nicht betroffen. Die Namensräume sind jedoch als Voraussetzungen für die Zuordnung eines einzelnen Knotens zu berücksichtigen.
Für die Zuordnung eines Knoten aus dem Baum zu einem Datenfeld gelten daher folgende Voraussetzungen:
Die gleiche Art des Knotens im Baum und in der IDENTIFIED-Klausel des Datenfeldes (d.h. beide sind Element-Knoten bzw. Attribut-Knoten)
Der in der IDENTIFIED-Klausel angegebene lokale Namen muss mit dem lokalen Namen des Knotens im Baum übereinstimmen:
Bei einer BY-Angabe müssen die Namen identisch sein, abgesehen von endständigen Leerzeichen.
Bei einer USING-Angabe wird jeder beliebige Name aus dem Baum als übereinstimmend angesehen.
Der in der IDENTIFIED-Klausel angegebene Namensraum muss mit dem Namensraum des Knotens im Baum übereinstimmen (dabei spielt es keine Rolle, ob die NAMESPACE-Angabe für das Datenfeld explizit gemacht ist, oder geerbt wurde; gleiches gilt für die namespaces im XML-Baum):
Bei einer IS-Angabe müssen die Namensräume identisch sein, abgesehen von endständigen Leerzeichen.
Bei einer USING-Angabe wird jeder beliebige Namensraum aus dem Baum als übereinstimmend angesehen, auch der leere Namensraum.
Bei der Angabe NULL muss der Knoten im Baum einen leeren Namensraum haben.
Beispiel 12-55 Vorgebener NAMESPACE
XML-Dokument | Pos | COBOL-Datenstruktur |
|
|
| 1 2 3 4 |
| | |
| 00 | 08 |
Anmerkungen:
Hinweise zur Darstellung dieses Beispiels finden Sie auf "Anweisungen für die XML-Verarbeitung".
Knoten 1 und Datenfeld x geben explizit den gleichen Namensraum an. Da auch die Elementnamen gleich sind, kann Knoten1 zugeordnet werden.
Die NAMESPACE-Angabe bei Datenfeld y ist eigentlich überflüssig, da sie identisch ist mit derjenigen des übergeordneten Datenfeldes x. y würde ohne eigene Angabe den Namensraum von x erben.
Knoten 2 erbt den Standard-Namensraum von Knoten1 und hat somit den gleichen Namensraum wie Datenfeld y. Da auch die Elementnamen gleich sind, kann Knoten 2 zugeordnet werden.
Knoten 3 und Datenfeld u haben zwar den gleichen lokalen Namen (b), Knoten 3 erbt jedoch den Namensraum http://www.abc, während Datenfeld u explizit den leeren Namensraum verlangt. Knoten 3 kann also nicht zugeordnet werden.
Knoten 4 und Datenfeld z haben ebenfalls den gleichen lokalen Namen (c). Knoten 4 gibt jedoch explizit den Namensraum http://www.efg an, während Datenfeld z als Element ohne eigene NAMESPACE-Angabe den Namensraum http://abc des übergeordneten Datenfeldes x erbt. Da die Namensräume verschieden sind, kann Knoten4 nicht zugeordnet werden.
Beim Lesen über x lassen sich die Knoten 3 und 4 nie zuordnen und bewirken den Ein-/Ausgabe-Zustand 08.
Beispiel 12-56 Beliebiger NAMESPACE
XML-Dokument | Pos | COBOL-Datenstruktur |
|
|
|
| 1 2 3 4 |
| | | 3(r) c'BLANK''BLANK' http://www.efg 4 |
| 00 | 00 | 00 |
1 Das Symbol 'BLANK' wird 14 mal wiederholt.
Anmerkungen:
Hinweise zur Darstellung dieses Beispiels finden Sie auf "Anweisungen für die XML-Verarbeitung".
Weder der Elementname, noch der Namensraum macht Vorgaben. Daher lassen sich alle Knoten prinzipiell zuordnen. Aus diesem Grund liefert die erste READ-Anweisung (anders als in Beispiel 12-55) den Ein-/Ausgabe-Zustand 00.
Knoten 1 hat keinen (d.h. einen leeren) Namensraum: Für die Übertragung in das Datenfeld x-nsp wirkt er wie ein Sendefeld mit der Länge Null. Daher die Leerzeichen in x-nsp. Gleiches gilt für Knoten 2 und y-nsp.
Die zweite READ-Anweisung liest Knoten 3: Als Elementname wird in y-name nur der lokale Name 'c' geliefert. Als Namensraum wird der komplette Namensraum aus der zugehörigen xmlns-Angabe (bei Knoten 1) geliefert. Das zur Abkürzung verwendete Präfix 'r' ist in COBOL nicht sichtbar.